 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Multi-Hop Reasoning Really Explainable? Towards Benchmarking Reasoning Interpretability
Paper and Code
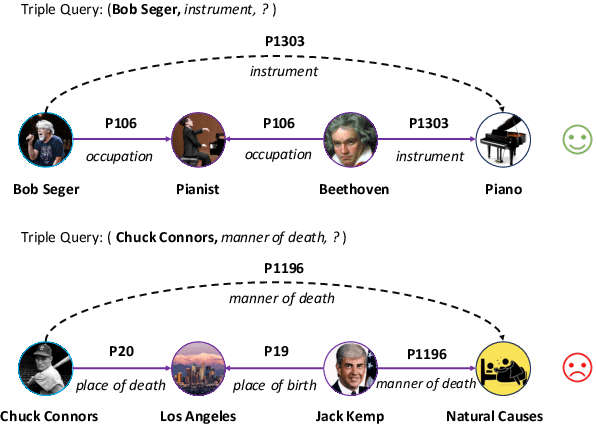


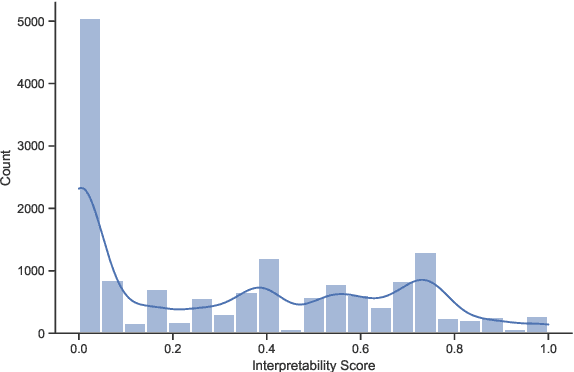
Multi-hop reasoning has been widely studied in recent years to obtain more interpretable link prediction. However, we find in experiments that many paths given by these models are actually unreasonable, while little works have been done on interpretability evaluation for them. In this paper, we propose a unified framework to quantitatively evaluate the interpretability of multi-hop reasoning models so as to advance their development. In specific, we define three metrics including path recall, local interpretability, and global interpretability for evaluation, and design an approximate strategy to calculate them using the interpretability scores of rules. Furthermore, we manually annotate all possible rules and establish a Benchmark to detect the Interpretability of Multi-hop Reasoning (BIMR). In experiments, we run nine baselines on our benchmark. The experimental results show that the interpretability of current multi-hop reasoning models is less satisfactory and is still far from the upper bound given by our benchmark. Moreover, the rule-based models outperform the multi-hop reasoning models in terms of performance and interpretability, which points to a direction for future research, i.e., we should investigate how to better incorporate rule information into the multi-hop reasoning model. Our codes and datasets can be obtained from https://github.com/THU-KEG/BIMR.