 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Text Retrieval via Joint Text Detection and Similarity Learning
Paper and Code
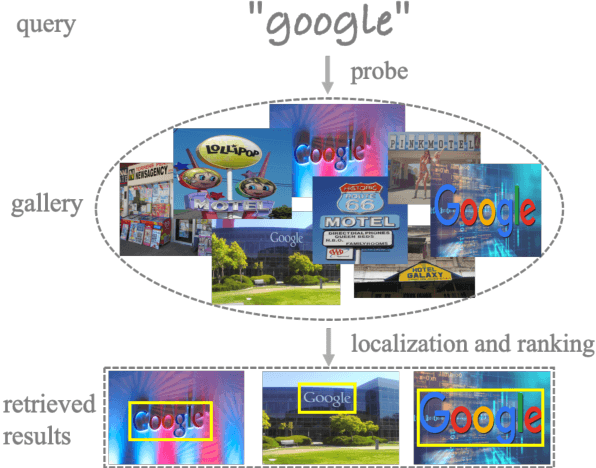

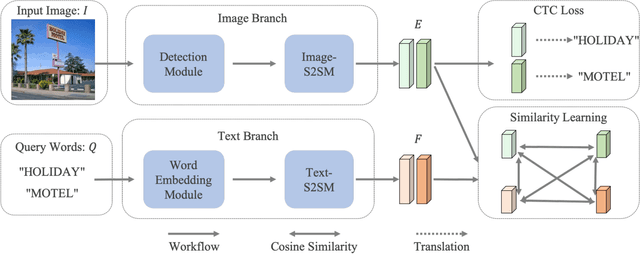
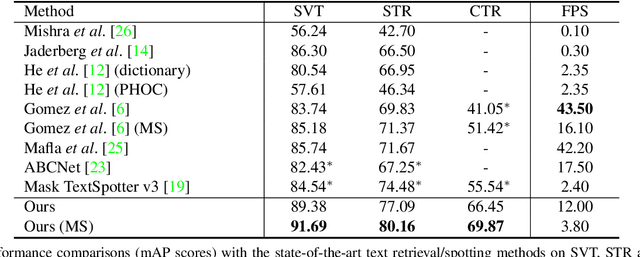
Scene text retrieval aims to localize and search all text instances from an image gallery, which are the same or similar to a given query text. Such a task is usually realized by matching a query text to the recognized words, outputted by an end-to-end scene text spotter. In this paper, we address this problem by directly learning a cross-modal similarity between a query text and each text instance from natural images. Specifically, we establish an end-to-end trainable network, jointly optimizing the procedures of scene text detection and cross-modal similarity learning. In this way, scene text retrieval can be simply performed by ranking the detected text instances with the learned similarity. Experiments on three benchmark datasets demonstrate our method consistently outperforms the state-of-the-art scene text spotting/retrieval approaches. In particular, the proposed framework of joint detection and similarity learning achieves significantly better performance than separated methods. Code is available at: https://github.com/lanfeng4659/STR-TDSL.