 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Energy-Based Models for End-to-End Speech Recognition
Paper and Code
Mar 25, 2021


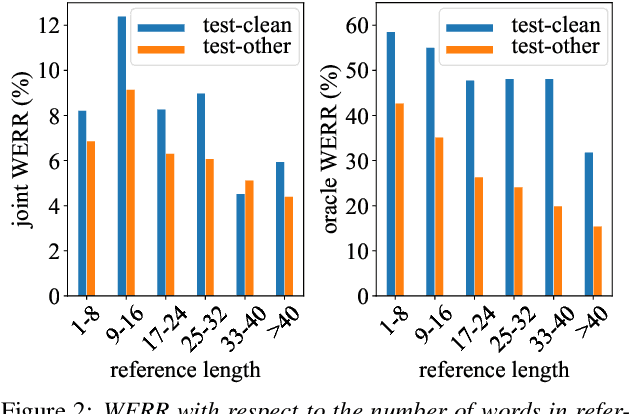
End-to-end models with auto-regressive decoders have shown impressive results for automatic speech recognition (ASR). These models formulate the sequence-level probability as a product of the conditional probabilities of all individual tokens given their histories. However, the performance of locally normalised models can be sub-optimal because of factors such as exposure bias. Consequently, the model distribution differs from the underlying data distribution. In this paper, the residual energy-based model (R-EBM) is proposed to complement the auto-regressive ASR model to close the gap between the two distributions. Meanwhile, R-EBMs can also be regarded as utterance-level confidence estimators, which may benefit many downstream tasks. Experiments on a 100hr LibriSpeech dataset show that R-EBMs can reduce the word error rates (WERs) by 8.2%/6.7% while improving areas under precision-recall curves of confidence scores by 12.6%/28.4% on test-clean/test-other sets. Furthermore, on a state-of-the-art model using self-supervised learning (wav2vec 2.0), R-EBMs still significantly improves both the WER and confidence estimation performance.