 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMix: Unveiling the Power of Mixup
Paper and Code

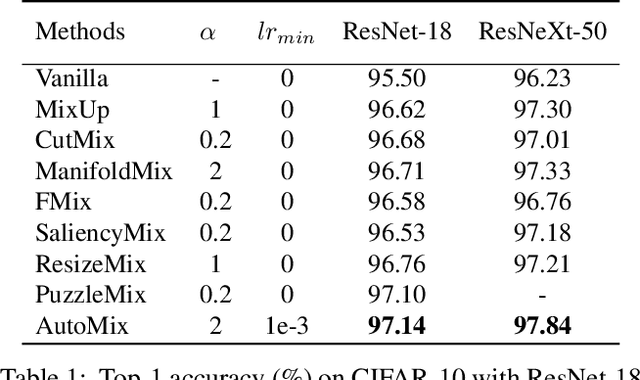
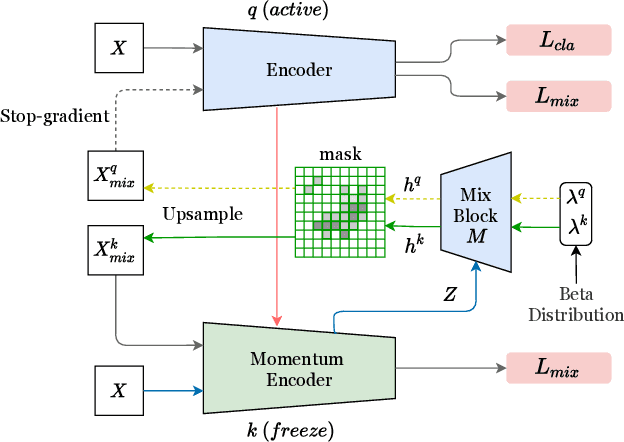
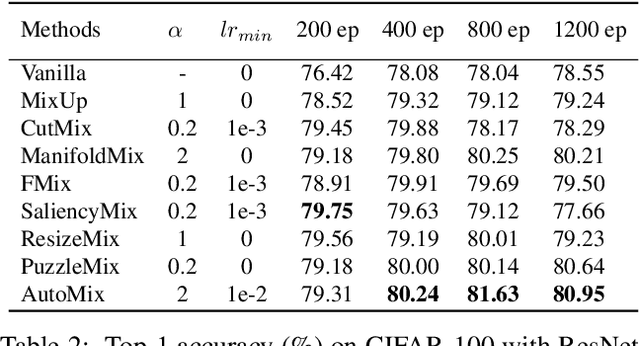
Mixup-based data augmentation has achieved great success as regularizer for deep neural networks. However, existing mixup methods require explicitly designed mixup policies. In this paper, we present a flexible, general Automatic Mixup (AutoMix) framework which utilizes discriminative features to learn a sample mixing policy adaptively. We regard mixup as a pretext task and split it into two sub-problems: mixed samples generation and mixup classification. To this end, we design a lightweight mix block to generate synthetic samples based on feature maps and mix labels. Since the two sub-problems are in the nature of Expectation-Maximization (EM), we also propose a momentum training pipeline to optimize the mixup process and mixup classification process alternatively in an end-to-end fashion. Extensive experiments on six popular classification benchmarks show that AutoMix consistently outperforms other leading mixup methods and improves generalization abilities to downstream tasks. We hope AutoMix will motivate the community to rethink the role of mixup in representation learning. The code will be released soon.