 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBossNAS: Exploring Hybrid CNN-transformers with Block-wisely Self-supervised Neural Architecture Search
Paper and Code
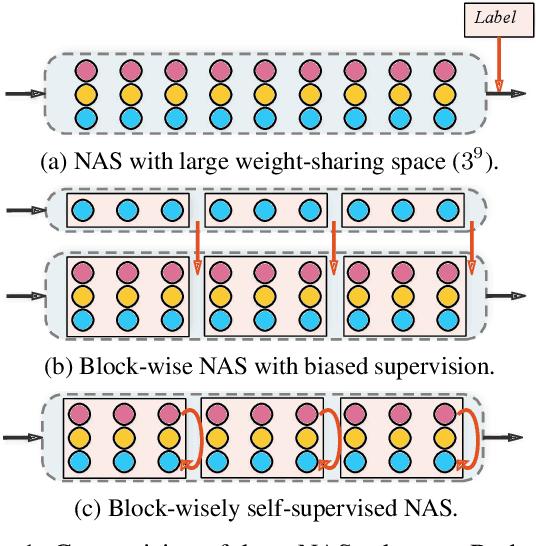
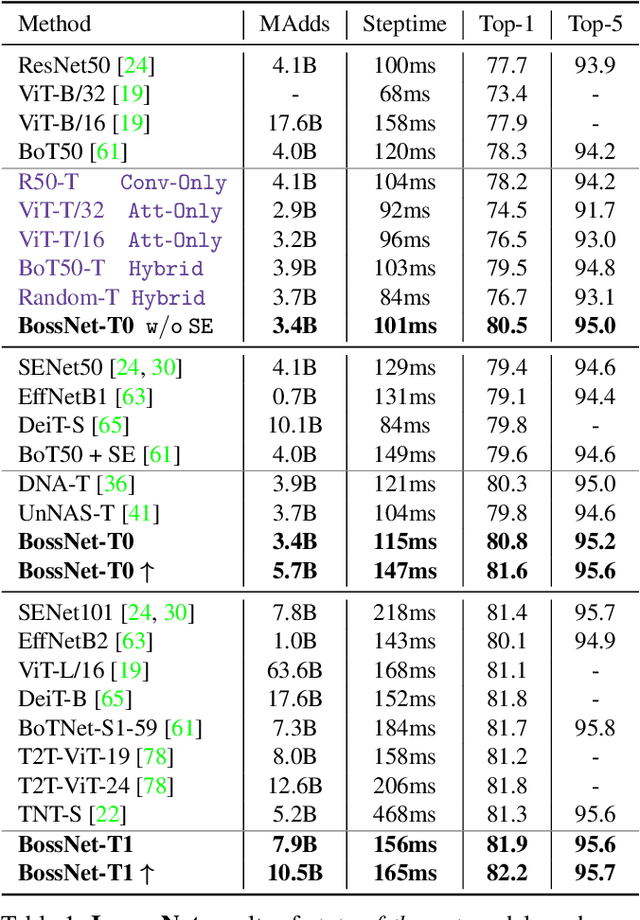
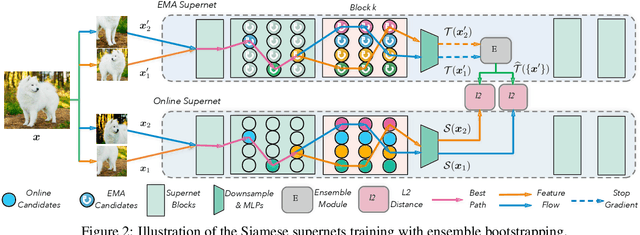
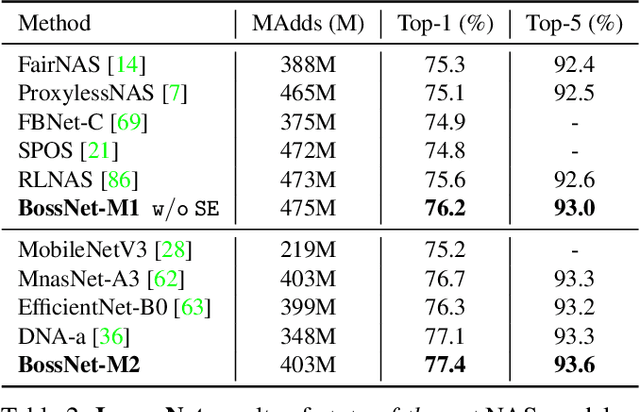
A myriad of recent breakthroughs in hand-crafted neural architectures for visual recognition have highlighted the urgent need to explore hybrid architectures consisting of diversified building blocks. Meanwhile, neural architecture search methods are surging with an expectation to reduce human efforts. However, whether NAS methods can efficiently and effectively handle diversified search spaces with disparate candidates (e.g. CNNs and transformers) is still an open question. In this work, we present Block-wisely Self-supervised Neural Architecture Search (BossNAS), an unsupervised NAS method that addresses the problem of inaccurate architecture rating caused by large weight-sharing space and biased supervision in previous methods. More specifically, we factorize the search space into blocks and utilize a novel self-supervised training scheme, named ensemble bootstrapping, to train each block separately before searching them as a whole towards the population center. Additionally, we present HyTra search space, a fabric-like hybrid CNN-transformer search space with searchable down-sampling positions. On this challenging search space, our searched model, BossNet-T, achieves up to 82.2% accuracy on ImageNet, surpassing EfficientNet by 2.1% with comparable compute time. Moreover, our method achieves superior architecture rating accuracy with 0.78 and 0.76 Spearman correlation on the canonical MBConv search space with ImageNet and on NATS-Bench size search space with CIFAR-100, respectively, surpassing state-of-the-art NAS methods. Code and pretrained models are available at https://github.com/changlin31/BossNAS .