 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Scene Memory for Vision-Language Navigation
Paper and Code
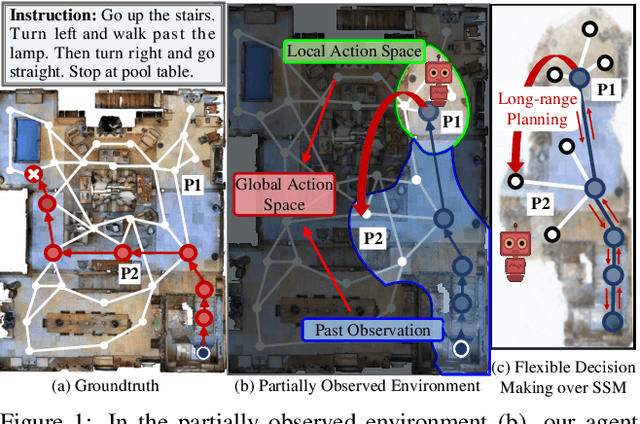
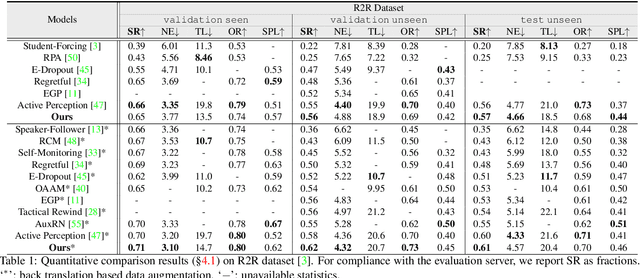
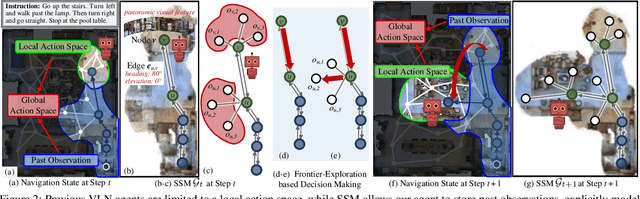
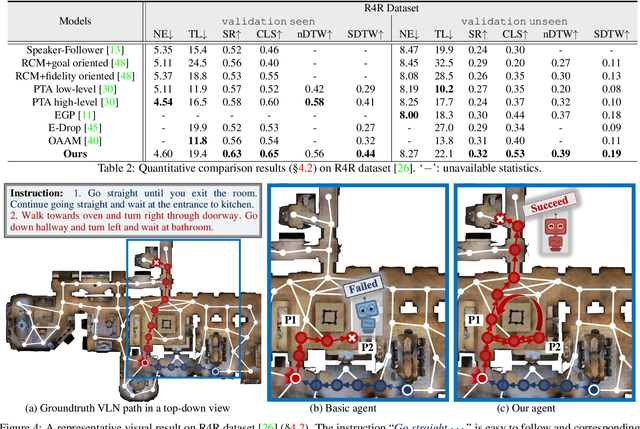
Recently, numerous algorithms have been developed to tackle the problem of vision-language navigation (VLN), i.e., entailing an agent to navigate 3D environments through following linguistic instructions. However, current VLN agents simply store their past experiences/observations as latent states in recurrent networks, failing to capture environment layouts and make long-term planning. To address these limitations, we propose a crucial architecture, called Structured Scene Memory (SSM). It is compartmentalized enough to accurately memorize the percepts during navigation. It also serves as a structured scene representation, which captures and disentangles visual and geometric cues in the environment. SSM has a collect-read controller that adaptively collects information for supporting current decision making and mimics iterative algorithms for long-range reasoning. As SSM provides a complete action space, i.e., all the navigable places on the map, a frontier-exploration based navigation decision making strategy is introduced to enable efficient and global planning. Experiment results on two VLN datasets (i.e., R2R and R4R) show that our method achieves state-of-the-art performance on several metrics.