 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Models
Paper and Code
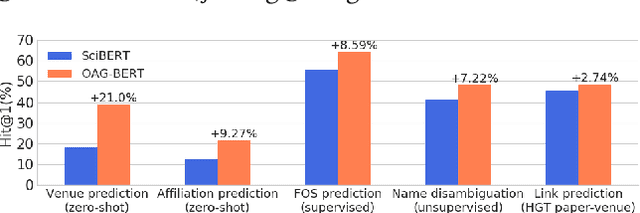
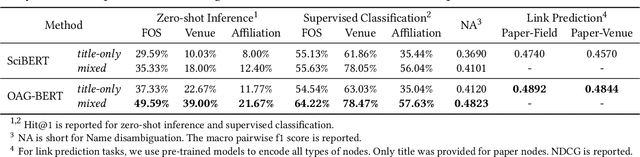
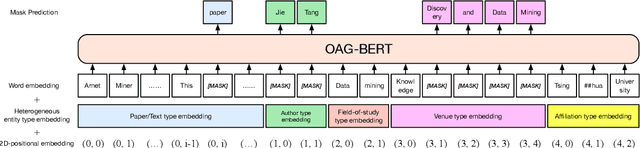
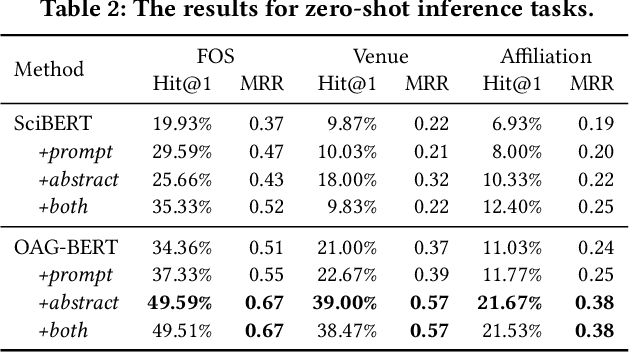
To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations and paper tagging in the AMiner system. It is also available to the public through the CogDL package.