 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
Paper and Code
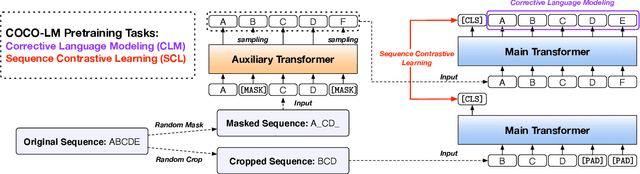
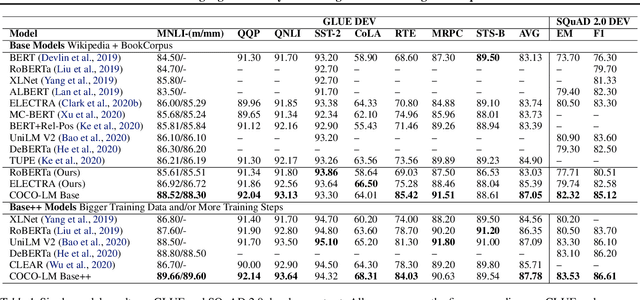
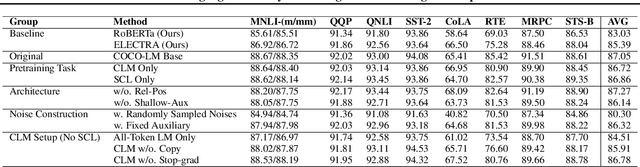
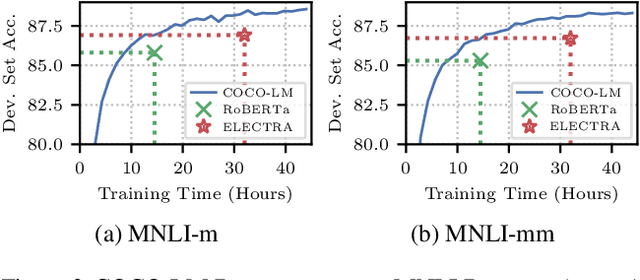
We present COCO-LM, a new self-supervised learning framework that pretrains Language Models by COrrecting challenging errors and COntrasting text sequences. COCO-LM employs an auxiliary language model to mask-and-predict tokens in original text sequences. It creates more challenging pretraining inputs, where noises are sampled based on their likelihood in the auxiliary language model. COCO-LM then pretrains with two tasks: The first task, corrective language modeling, learns to correct the auxiliary model's corruptions by recovering the original tokens. The second task, sequence contrastive learning, ensures that the language model generates sequence representations that are invariant to noises and transformations. In our experiments on the GLUE and SQuAD benchmarks, COCO-LM outperforms recent pretraining approaches in various pretraining settings and few-shot evaluations, with higher pretraining efficiency. Our analyses reveal that COCO-LM's advantages come from its challenging training signals, more contextualized token representations, and regularized sequence representations.