 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized RNN beamformer for target speech separation
Paper and Code
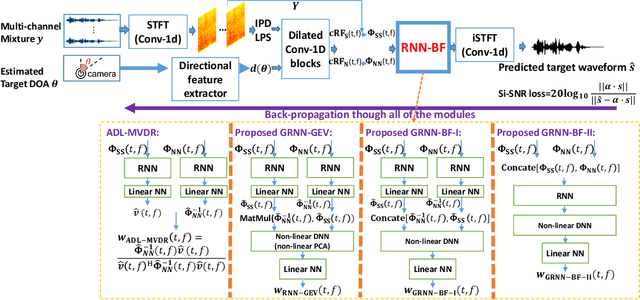
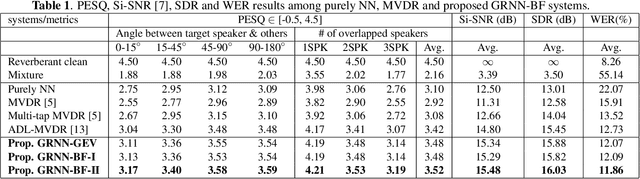
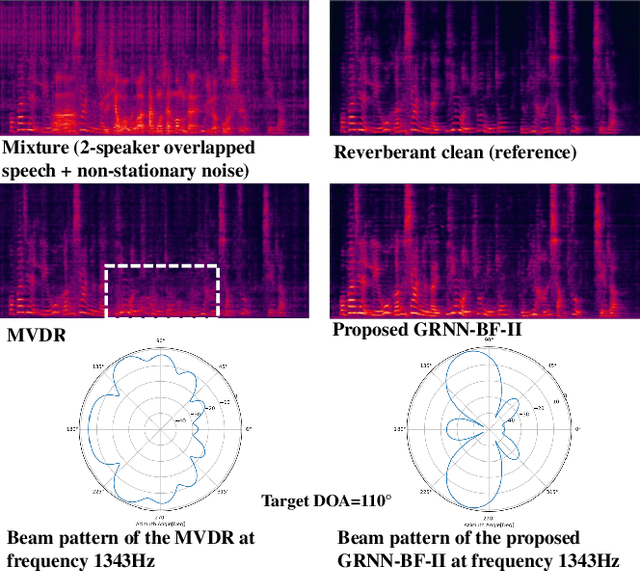
Recently we proposed an all-deep-learning minimum variance distortionless response (ADL-MVDR) method where the unstable matrix inverse and principal component analysis (PCA) operations in the MVDR were replaced by recurrent neural networks (RNNs). However, it is not clear whether the success of the ADL-MVDR is owed to the calculated covariance matrices or following the MVDR formula. In this work, we demonstrate the importance of the calculated covariance matrices and propose three types of generalized RNN beamformers (GRNN-BFs) where the beamforming solution is beyond the MVDR and optimal. The GRNN-BFs could predict the frame-wise beamforming weights by leveraging on the temporal modeling capability of RNNs. The proposed GRNN-BF method obtains better performance than the state-of-the-art ADL-MVDR and the traditional mask-based MVDR methods in terms of speech quality (PESQ), speech-to-noise ratio (SNR), and word error rate (WER).