 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Contrastive Graph for Self-supervised Video Representation Learning
Paper and Code
Feb 01, 2021

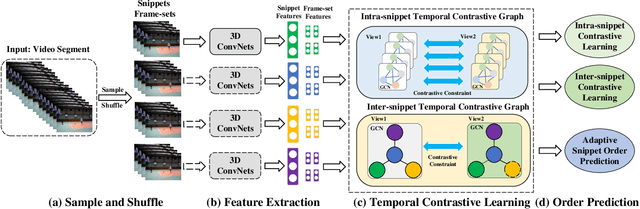

Attempt to fully explore the fine-grained temporal structure and global-local chronological characteristics for self-supervised video representation learning, this work takes a closer look at exploiting the temporal structure of videos and further proposes a novel self-supervised method named Temporal Contrastive Graph (TCG). In contrast to the existing methods that randomly shuffle the video frames or video snippets within a video, our proposed TCG roots in a hybrid graph contrastive learning strategy to regard the inter-snippet and intra-snippet temporal relationships as self-supervision signals for temporal representation learning. To increase the temporal diversity of features more comprehensively and precisely, our proposed TCG integrates the prior knowledge about the frame and snippet orders into temporal contrastive graph structures, i.e., the intra-/inter- snippet temporal contrastive graph modules. By randomly removing edges and masking node features of the intra-snippet graphs or inter-snippet graphs, our TCG can generate different correlated graph views. Then, specific contrastive losses are designed to maximize the agreement between node embeddings in different views. To learn the global context representation and recalibrate the channel-wise features adaptively, we introduce an adaptive video snippet order prediction module, which leverages the relational knowledge among video snippets to predict the actual snippet orders.Experimental results demonstrate the superiority of our TCG over the state-of-the-art methods on large-scale action recognition and video retrieval benchmarks.