 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Dialogue Utterance Rewriting as Sequence Tagging
Paper and Code

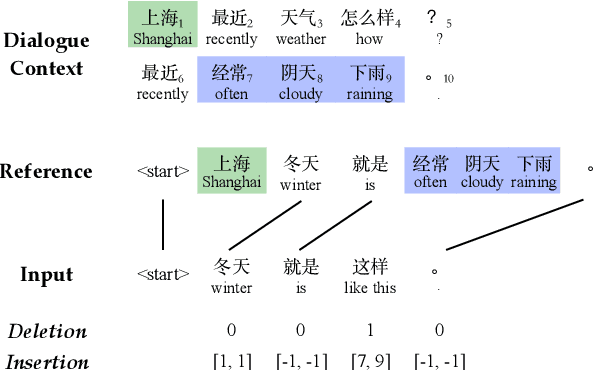
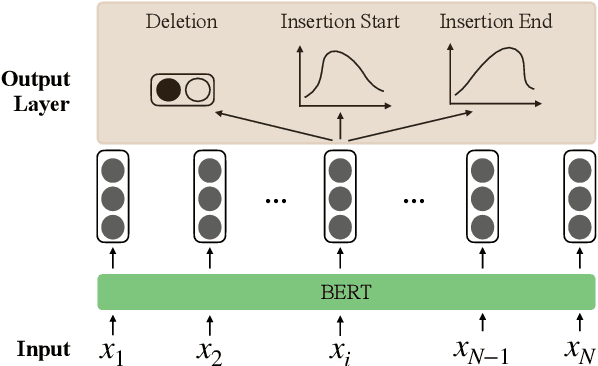

The task of dialogue rewriting aims to reconstruct the latest dialogue utterance by copying the missing content from the dialogue context. Until now, the existing models for this task suffer from the robustness issue, i.e., performances drop dramatically when testing on a different domain. We address this robustness issue by proposing a novel sequence-tagging-based model so that the search space is significantly reduced, yet the core of this task is still well covered. As a common issue of most tagging models for text generation, the model's outputs may lack fluency. To alleviate this issue, we inject the loss signal from BLEU or GPT-2 under a REINFORCE framework. Experiments show huge improvements of our model over the current state-of-the-art systems on domain transfer.