 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Optimal Neural Networks: Rapid Search in Diverse Spaces
Paper and Code
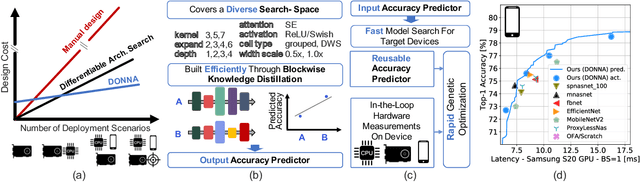



This work presents DONNA (Distilling Optimal Neural Network Architectures), a novel pipeline for rapid neural architecture search and search space exploration, targeting multiple different hardware platforms and user scenarios. In DONNA, a search consists of three phases. First, an accuracy predictor is built for a diverse search space using blockwise knowledge distillation. This predictor enables searching across diverse macro-architectural network parameters such as layer types, attention mechanisms, and channel widths, as well as across micro-architectural parameters such as block repeats, kernel sizes, and expansion rates. Second, a rapid evolutionary search phase finds a Pareto-optimal set of architectures in terms of accuracy and latency for any scenario using the predictor and on-device measurements. Third, Pareto-optimal models can be quickly finetuned to full accuracy. With this approach, DONNA finds architectures that outperform the state of the art. In ImageNet classification, architectures found by DONNA are 20% faster than EfficientNet-B0 and MobileNetV2 on a Nvidia V100 GPU at similar accuracy and 10% faster with 0.5% higher accuracy than MobileNetV2-1.4x on a Samsung S20 smartphone. In addition to neural architecture search, DONNA is used for search-space exploration and hardware-aware model compression.