 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSweep: An Evaluation Framework for Mitigating DNN Backdoor Attacks using Data Augmentation
Paper and Code
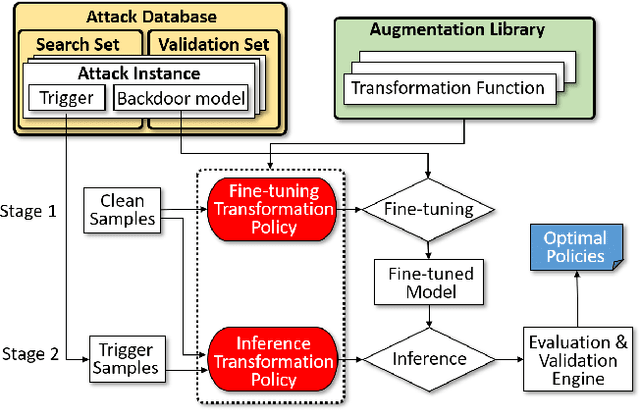
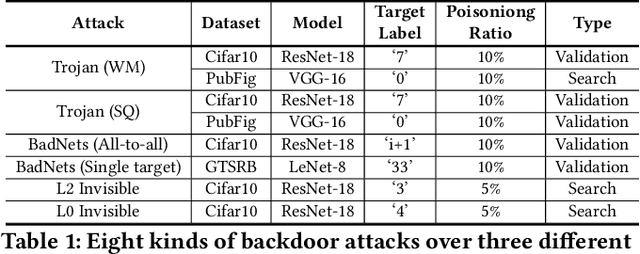

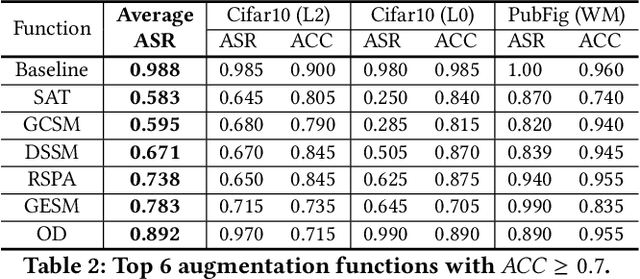
Public resources and services (e.g., datasets, training platforms, pre-trained models) have been widely adopted to ease the development of Deep Learning-based applications. However, if the third-party providers are untrusted, they can inject poisoned samples into the datasets or embed backdoors in those models. Such an integrity breach can cause severe consequences, especially in safety- and security-critical applications. Various backdoor attack techniques have been proposed for higher effectiveness and stealthiness. Unfortunately, existing defense solutions are not practical to thwart those attacks in a comprehensive way. In this paper, we investigate the effectiveness of data augmentation techniques in mitigating backdoor attacks and enhancing DL models' robustness. An evaluation framework is introduced to achieve this goal. Specifically, we consider a unified defense solution, which (1) adopts a data augmentation policy to fine-tune the infected model and eliminate the effects of the embedded backdoor; (2) uses another augmentation policy to preprocess input samples and invalidate the triggers during inference. We propose a systematic approach to discover the optimal policies for defending against different backdoor attacks by comprehensively evaluating 71 state-of-the-art data augmentation functions. Extensive experiments show that our identified policy can effectively mitigate eight different kinds of backdoor attacks and outperform five existing defense methods. We envision this framework can be a good benchmark tool to advance future DNN backdoor studies.