 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEARN++: Recurrent Dual-Domain Reconstruction Network for Compressed Sensing CT
Paper and Code
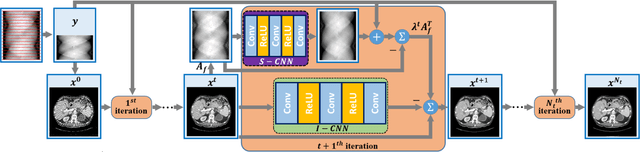
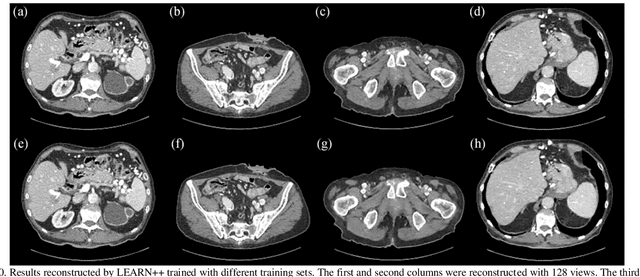
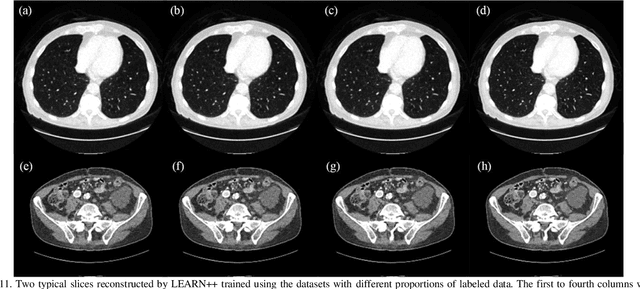
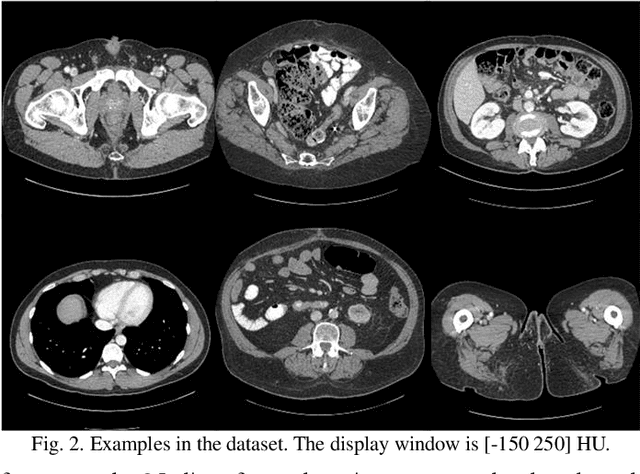
Compressed sensing (CS) computed tomography has been proven to be important for several clinical applications, such as sparse-view computed tomography (CT), digital tomosynthesis and interior tomography. Traditional compressed sensing focuses on the design of handcrafted prior regularizers, which are usually image-dependent and time-consuming. Inspired by recently proposed deep learning-based CT reconstruction models, we extend the state-of-the-art LEARN model to a dual-domain version, dubbed LEARN++. Different from existing iteration unrolling methods, which only involve projection data in the data consistency layer, the proposed LEARN++ model integrates two parallel and interactive subnetworks to perform image restoration and sinogram inpainting operations on both the image and projection domains simultaneously, which can fully explore the latent relations between projection data and reconstructed images. The experimental results demonstrate that the proposed LEARN++ model achieves competitive qualitative and quantitative results compared to several state-of-the-art methods in terms of both artifact reduction and detail preservation.