 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModels, Pixels, and Rewards: Evaluating Design Trade-offs in Visual Model-Based Reinforcement Learning
Paper and Code
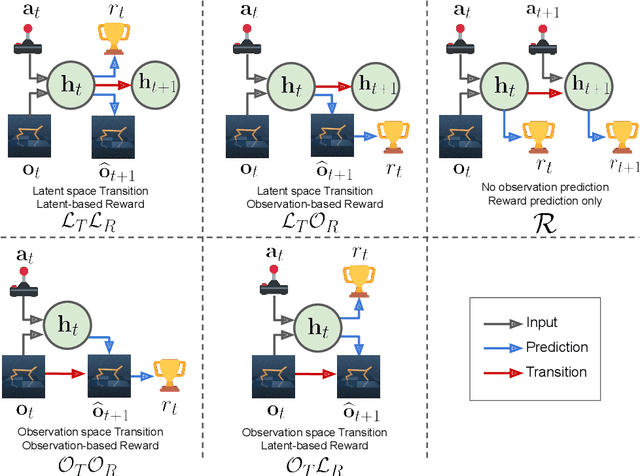

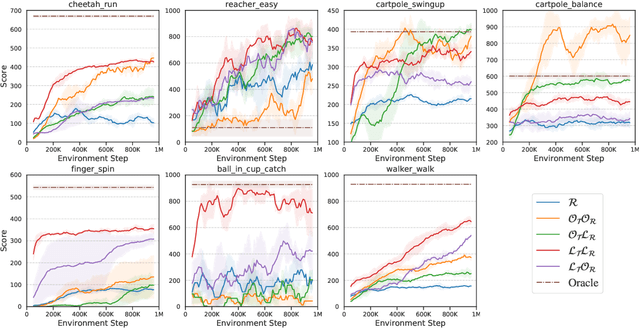
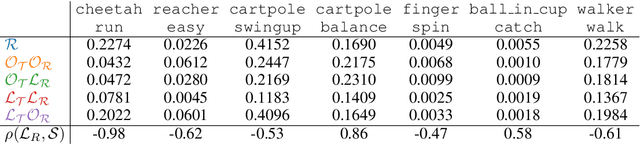
Model-based reinforcement learning (MBRL) methods have shown strong sample efficiency and performance across a variety of tasks, including when faced with high-dimensional visual observations. These methods learn to predict the environment dynamics and expected reward from interaction and use this predictive model to plan and perform the task. However, MBRL methods vary in their fundamental design choices, and there is no strong consensus in the literature on how these design decisions affect performance. In this paper, we study a number of design decisions for the predictive model in visual MBRL algorithms, focusing specifically on methods that use a predictive model for planning. We find that a range of design decisions that are often considered crucial, such as the use of latent spaces, have little effect on task performance. A big exception to this finding is that predicting future observations (i.e., images) leads to significant task performance improvement compared to only predicting rewards. We also empirically find that image prediction accuracy, somewhat surprisingly, correlates more strongly with downstream task performance than reward prediction accuracy. We show how this phenomenon is related to exploration and how some of the lower-scoring models on standard benchmarks (that require exploration) will perform the same as the best-performing models when trained on the same training data. Simultaneously, in the absence of exploration, models that fit the data better usually perform better on the downstream task as well, but surprisingly, these are often not the same models that perform the best when learning and exploring from scratch. These findings suggest that performance and exploration place important and potentially contradictory requirements on the model.