 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentional Separation-and-Aggregation Network for Self-supervised Depth-Pose Learning in Dynamic Scenes
Paper and Code
Nov 18, 2020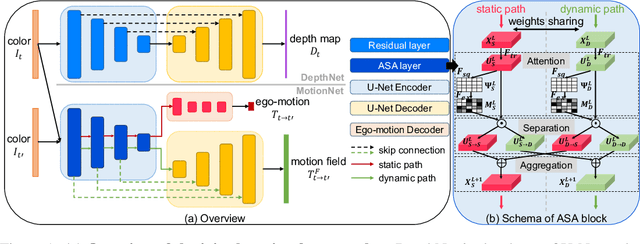
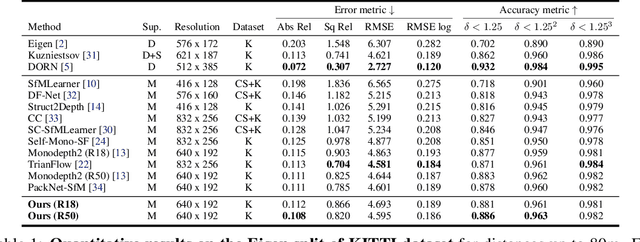


Learning depth and ego-motion from unlabeled videos via self-supervision from epipolar projection can improve the robustness and accuracy of the 3D perception and localization of vision-based robots. However, the rigid projection computed by ego-motion cannot represent all scene points, such as points on moving objects, leading to false guidance in these regions. To address this problem, we propose an Attentional Separation-and-Aggregation Network (ASANet), which can learn to distinguish and extract the scene's static and dynamic characteristics via the attention mechanism. We further propose a novel MotionNet with an ASANet as the encoder, followed by two separate decoders, to estimate the camera's ego-motion and the scene's dynamic motion field. Then, we introduce an auto-selecting approach to detect the moving objects for dynamic-aware learning automatically. Empirical experiments demonstrate that our method can achieve the state-of-the-art performance on the KITTI benchmark.