 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfDeco: Self-Supervised Monocular Depth Completion in Challenging Indoor Environments
Paper and Code
Nov 10, 2020
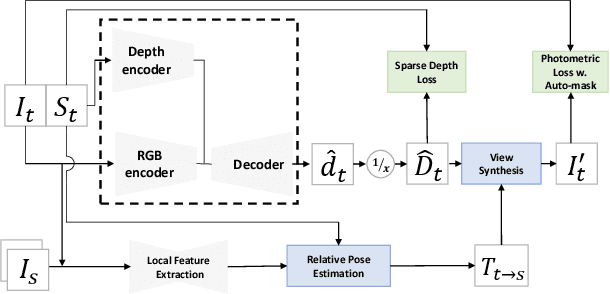

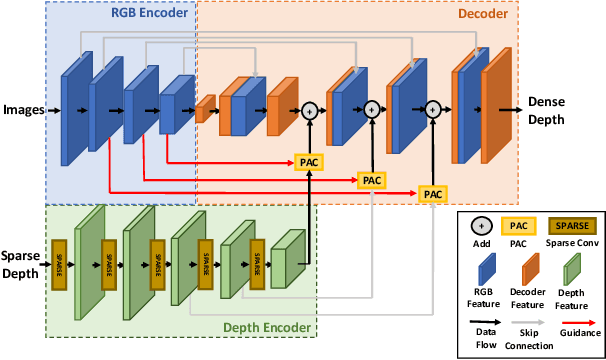
We present a novel algorithm for self-supervised monocular depth completion. Our approach is based on training a neural network that requires only sparse depth measurements and corresponding monocular video sequences without dense depth labels. Our self-supervised algorithm is designed for challenging indoor environments with textureless regions, glossy and transparent surface, non-Lambertian surfaces, moving people, longer and diverse depth ranges and scenes captured by complex ego-motions. Our novel architecture leverages both deep stacks of sparse convolution blocks to extract sparse depth features and pixel-adaptive convolutions to fuse image and depth features. We compare with existing approaches in NYUv2, KITTI and NAVERLABS indoor datasets, and observe 5\:-\:34 \% improvements in root-means-square error (RMSE) reduction.