 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Summarization of Open-Domain Podcast Episodes
Paper and Code
Nov 12, 2020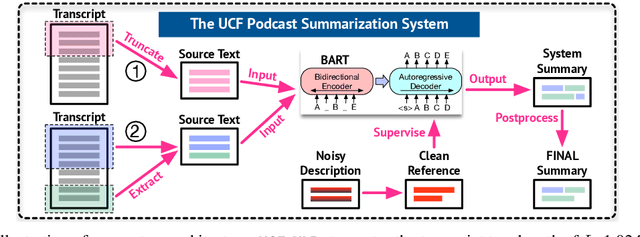



We present implementation details of our abstractive summarizers that achieve competitive results on the Podcast Summarization task of TREC 2020. A concise textual summary that captures important information is crucial for users to decide whether to listen to the podcast. Prior work focuses primarily on learning contextualized representations. Instead, we investigate several less-studied aspects of neural abstractive summarization, including (i) the importance of selecting important segments from transcripts to serve as input to the summarizer; (ii) striking a balance between the amount and quality of training instances; (iii) the appropriate summary length and start/end points. We highlight the design considerations behind our system and offer key insights into the strengths and weaknesses of neural abstractive systems. Our results suggest that identifying important segments from transcripts to use as input to an abstractive summarizer is advantageous for summarizing long documents. Our best system achieves a quality rating of 1.559 judged by NIST evaluators---an absolute increase of 0.268 (+21%) over the creator descriptions.