 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the limits of Concurrency in ML Training on Google TPUs
Paper and Code
Nov 07, 2020
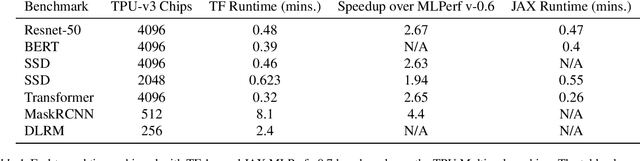
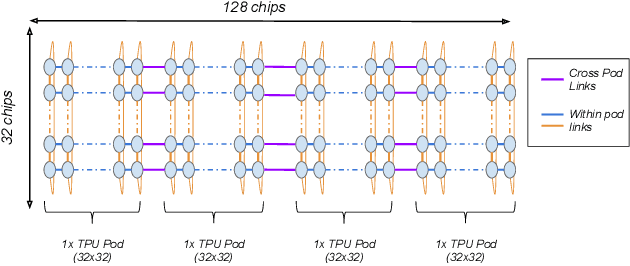
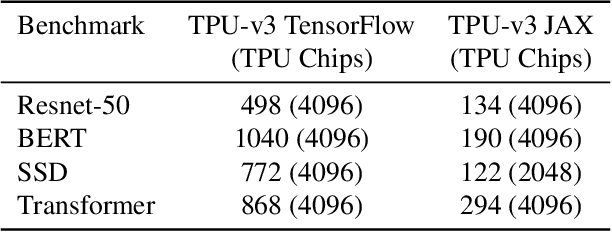
Recent results in language understanding using neural networks have required training hardware of unprecedentedscale, with thousands of chips cooperating on a single training run. This paper presents techniques to scaleML models on the Google TPU Multipod, a mesh with 4096 TPU-v3 chips. We discuss model parallelism toovercome scaling limitations from the fixed batch size in data parallelism, communication/collective optimizations,distributed evaluation of training metrics, and host input processing scaling optimizations. These techniques aredemonstrated in both the TensorFlow and JAX programming frameworks. We also present performance resultsfrom the recent Google submission to the MLPerf-v0.7 benchmark contest, achieving record training times from16 to 28 seconds in four MLPerf models on the Google TPU-v3 Multipod machine.