 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Post Hoc Context for Faster Learning in Bandit Settings with Applications in Robot-Assisted Feeding
Paper and Code
Nov 05, 2020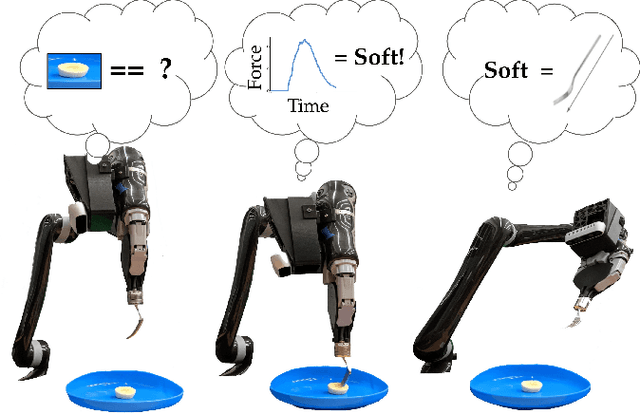
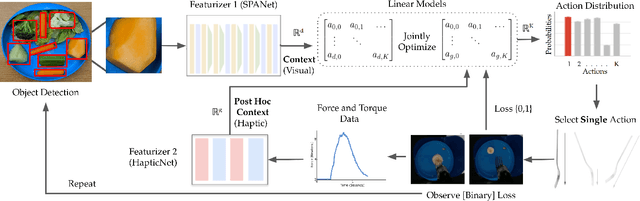


Autonomous robot-assisted feeding requires the ability to acquire a wide variety of food items. However, it is impossible for such a system to be trained on all types of food in existence. Therefore, a key challenge is choosing a manipulation strategy for a previously unseen food item. Previous work showed that the problem can be represented as a linear contextual bandit on visual information. However, food has a wide variety of multi-modal properties relevant to manipulation that can be hard to distinguish visually. Our key insight is that we can leverage the haptic information we collect during manipulation to learn some of these properties and more quickly adapt our visual model to previously unseen food. In general, we propose a modified linear contextual bandit framework augmented with post hoc context observed after action selection to empirically increase learning speed (as measured by cross-validation mean square error) and reduce cumulative regret. Experiments on synthetic data demonstrate that this effect is more pronounced when the dimensionality of the context is large relative to the post hoc context or when the post hoc context model is particularly easy to learn. Finally, we apply this framework to the bite acquisition problem and demonstrate the acquisition of 8 previously unseen types of food with 21% fewer failures across 64 attempts.