 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics Randomization Revisited:A Case Study for Quadrupedal Locomotion
Paper and Code
Nov 04, 2020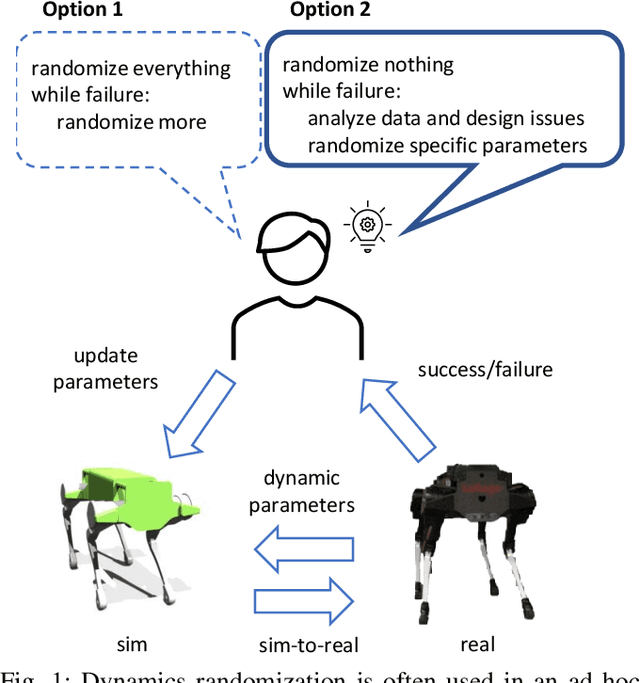
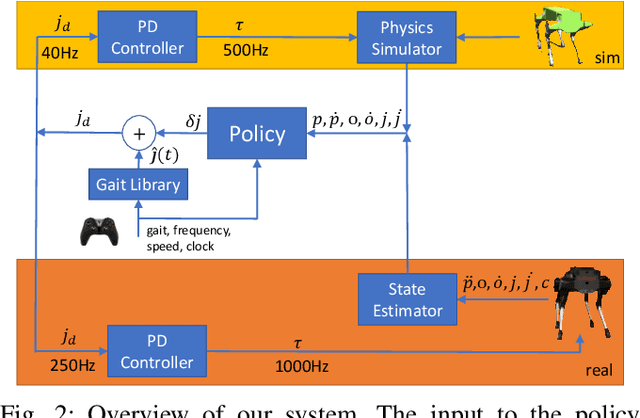

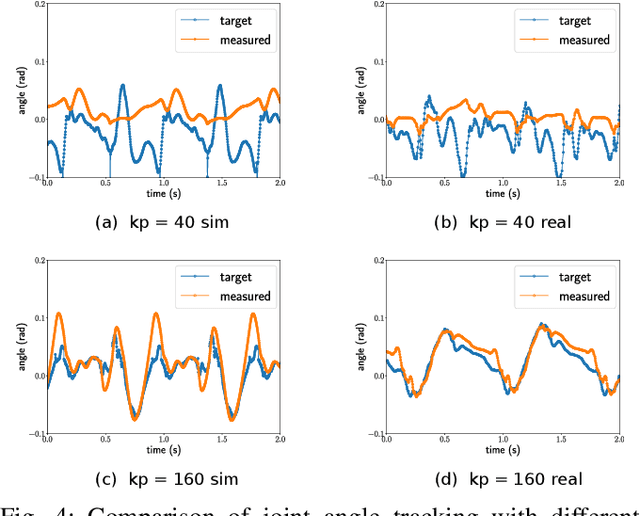
Understanding the gap between simulation andreality is critical for reinforcement learning with legged robots,which are largely trained in simulation. However, recent workhas resulted in sometimes conflicting conclusions with regardto which factors are important for success, including therole of dynamics randomization. In this paper, we aim toprovide clarity and understanding on the role of dynamicsrandomization in learning robust locomotion policies for theLaikago quadruped robot. Surprisingly, in contrast to priorwork with the same robot model, we find that direct sim-to-real transfer is possible without dynamics randomizationor on-robot adaptation schemes. We conduct extensive abla-tion studies in a sim-to-sim setting to understand the keyissues underlying successful policy transfer, including otherdesign decisions that can impact policy robustness. We furtherground our conclusions via sim-to-real experiments with variousgaits, speeds, and stepping frequencies. Additional Details: https://www.pair.toronto.edu/understanding-dr/.