 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Self-Distilling Graph Neural Network
Paper and Code
Nov 04, 2020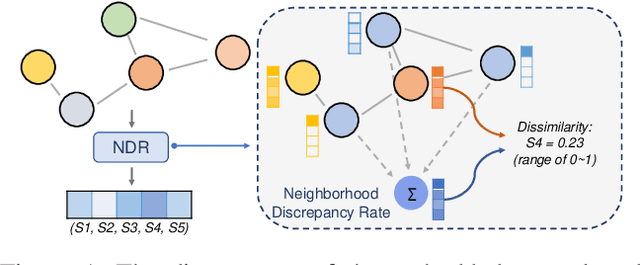
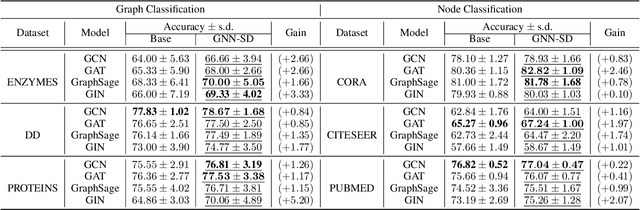
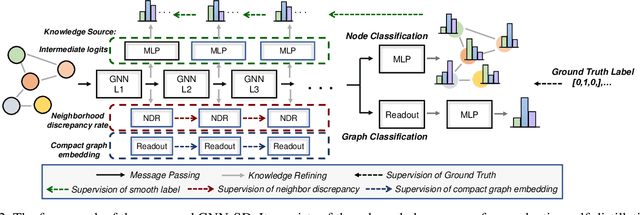
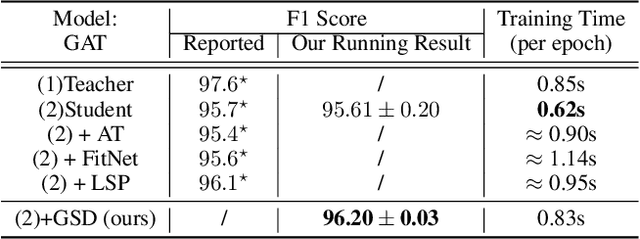
Recently, the teacher-student knowledge distillation framework has demonstrated its potential in training Graph Neural Networks (GNNs). However, due to the difficulty of training deep and wide GNN models, one can not always obtain a satisfactory teacher model for distillation. Furthermore, the inefficient training process of teacher-student knowledge distillation also impedes its applications in GNN models. In this paper, we propose the first teacher-free knowledge distillation framework for GNNs, termed GNN Self-Distillation (GNN-SD), that serves as a drop-in replacement for improving the training process of GNNs.We design three knowledge sources for GNN-SD: neighborhood discrepancy rate (NDR), compact graph embedding and intermediate logits. Notably, serving as a metric of the non-smoothness of the embedded graph, NDR empowers the transferability of knowledge that maintains high neighborhood discrepancy by enforcing consistency between consecutive GNN layers. We conduct exploring analysis to verify that our framework could improve the training dynamics and embedding quality of GNNs. Extensive experiments on various popular GNN models and datasets demonstrate that our approach obtains consistent and considerable performance enhancement, proving its effectiveness and generalization ability.