 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
Paper and Code


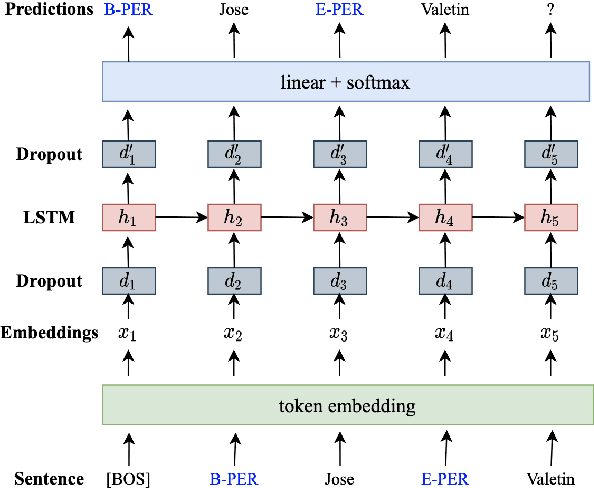
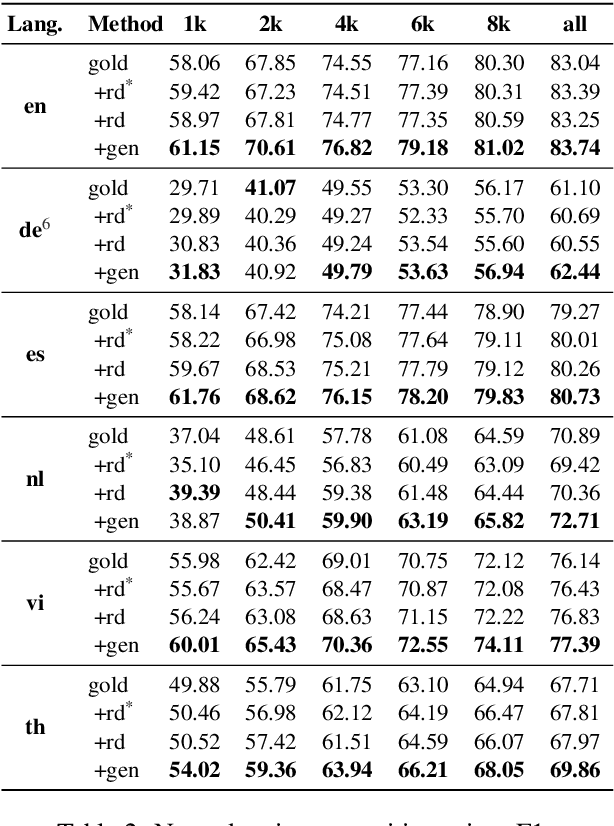
Data augmentation techniques have been widely used to improve machine learning performance as they enhance the generalization capability of models. In this work, to generate high quality synthetic data for low-resource tagging tasks, we propose a novel augmentation method with language models trained on the linearized labeled sentences. Our method is applicable to both supervised and semi-supervised settings. For the supervised settings, we conduct extensive experiments on named entity recognition (NER), part of speech (POS) tagging and end-to-end target based sentiment analysis (E2E-TBSA) tasks. For the semi-supervised settings, we evaluate our method on the NER task under the conditions of given unlabeled data only and unlabeled data plus a knowledge base. The results show that our method can consistently outperform the baselines, particularly when the given gold training data are less.