 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate and Consistent Evaluation: A Dataset for Distantly-Supervised Relation Extraction
Paper and Code
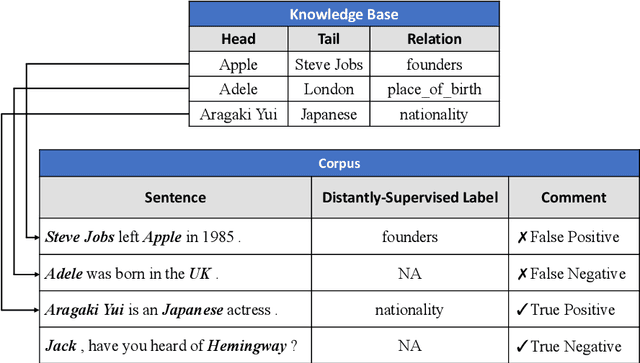

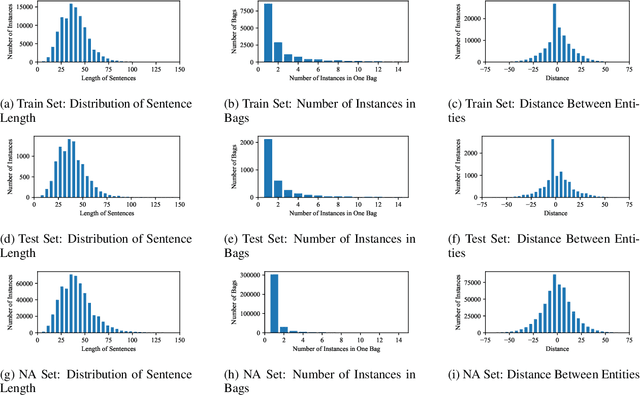
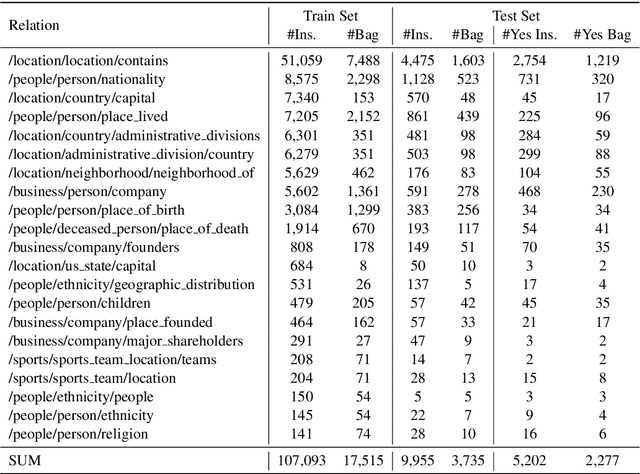
In recent years, distantly-supervised relation extraction has achieved a certain success by using deep neural networks. Distant Supervision (DS) can automatically generate large-scale annotated data by aligning entity pairs from Knowledge Bases (KB) to sentences. However, these DS-generated datasets inevitably have wrong labels that result in incorrect evaluation scores during testing, which may mislead the researchers. To solve this problem, we build a new dataset NYTH, where we use the DS-generated data as training data and hire annotators to label test data. Compared with the previous datasets, NYT-H has a much larger test set and then we can perform more accurate and consistent evaluation. Finally, we present the experimental results of several widely used systems on NYT-H. The experimental results show that the ranking lists of the comparison systems on the DS-labelled test data and human-annotated test data are different. This indicates that our human-annotated data is necessary for evaluation of distantly-supervised relation extraction.