Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Text Generation with Student-Forcing Optimal Transport
Paper and Code
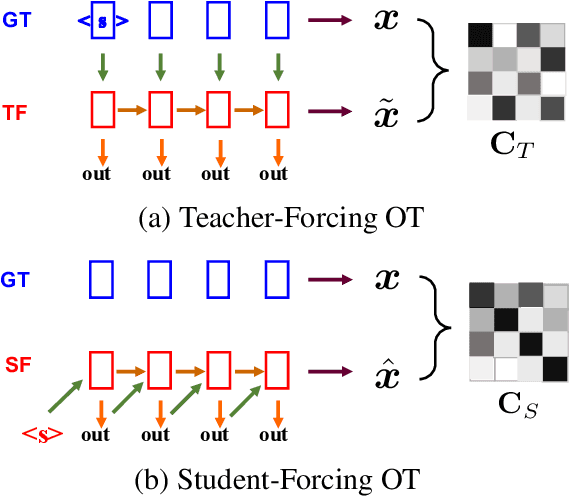
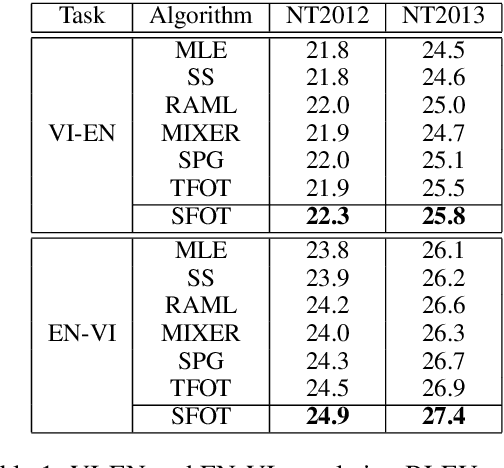
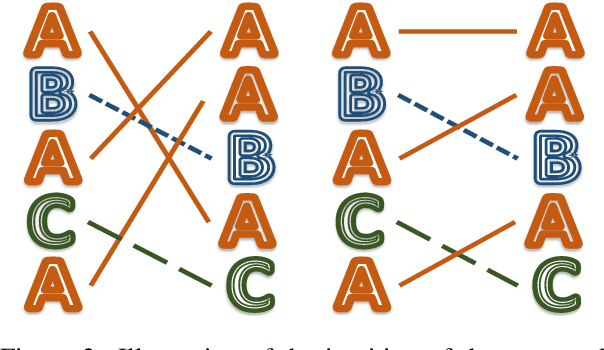
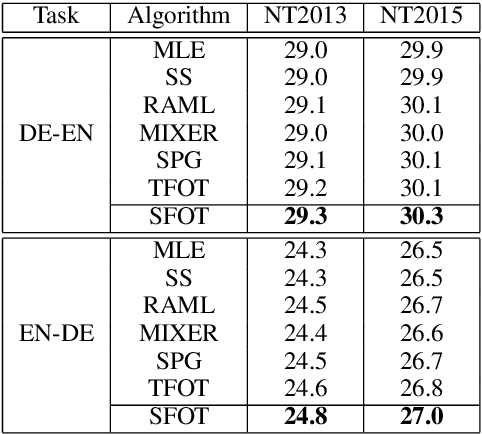
Neural language models are often trained with maximum likelihood estimation (MLE), where the next word is generated conditioned on the ground-truth word tokens. During testing, however, the model is instead conditioned on previously generated tokens, resulting in what is termed exposure bias. To reduce this gap between training and testing, we propose using optimal transport (OT) to match the sequences generated in these two modes. An extension is further proposed to improve the OT learning, based on the structural and contextual information of the text sequences. The effectiveness of the proposed method is validated on machine translation, text summarization, and text generation tasks.
* To appear at EMNLP 2020
View paper on