 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rewards from Linguistic Feedback
Paper and Code


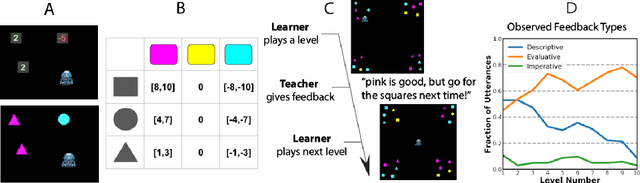
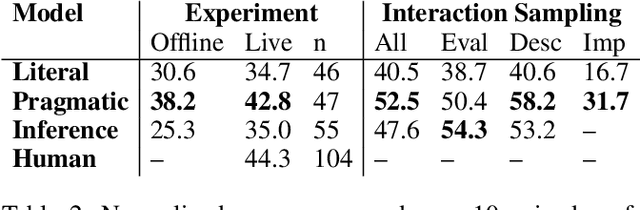
We explore unconstrained natural language feedback as a learning signal for artificial agents. Humans use rich and varied language to teach, yet most prior work on interactive learning from language assumes a particular form of input (e.g. commands). We propose a general framework which does not make this assumption. We decompose linguistic feedback into two components: a grounding to $\textit{features}$ of a Markov decision process and $\textit{sentiment}$ about those features. We then perform an analogue of inverse reinforcement learning, regressing the teacher's sentiment on the features to infer their latent reward function. To evaluate our approach, we first collect a corpus of teaching behavior in a cooperative task where both teacher and learner are human. We use our framework to implement two artificial learners: a simple "literal" model and a "pragmatic" model with additional inductive biases. We baseline these with a neural network trained end-to-end to predict latent rewards. We then repeat our initial experiment pairing human teachers with our models. We find our "literal" and "pragmatic" models successfully learn from live human feedback and offer statistically-significant performance gains over the end-to-end baseline, with the "pragmatic" model approaching human performance on the task. Inspection reveals the end-to-end network learns representations similar to our models, suggesting they reflect emergent properties of the data. Our work thus provides insight into the information structure of naturalistic linguistic feedback as well as methods to leverage it for reinforcement learning.