 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraPPa: Grammar-Augmented Pre-Training for Table Semantic Parsing
Paper and Code
Sep 29, 2020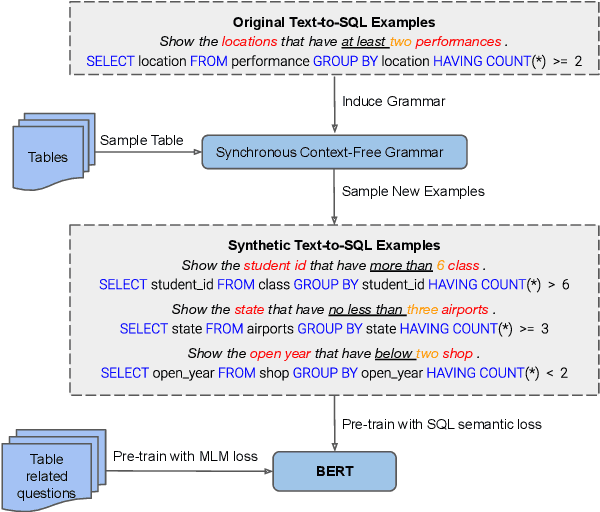


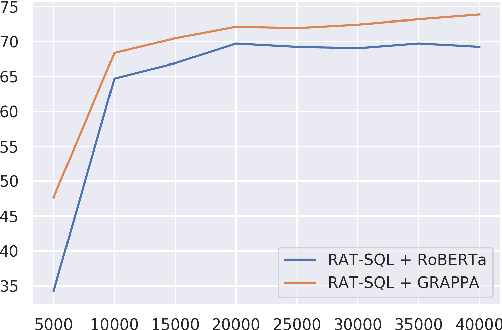
We present GraPPa, an effective pre-training approach for table semantic parsing that learns a compositional inductive bias in the joint representations of textual and tabular data. We construct synthetic question-SQL pairs over high-quality tables via a synchronous context-free grammar (SCFG) induced from existing text-to-SQL datasets. We pre-train our model on the synthetic data using a novel text-schema linking objective that predicts the syntactic role of a table field in the SQL for each question-SQL pair. To maintain the model's ability to represent real-world data, we also include masked language modeling (MLM) over several existing table-and-language datasets to regularize the pre-training process. On four popular fully supervised and weakly supervised table semantic parsing benchmarks, GraPPa significantly outperforms RoBERTa-large as the feature representation layers and establishes new state-of-the-art results on all of them.