 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapped Q-learning with Context Relevant Observation Pruning to Generalize in Text-based Games
Paper and Code
Sep 24, 2020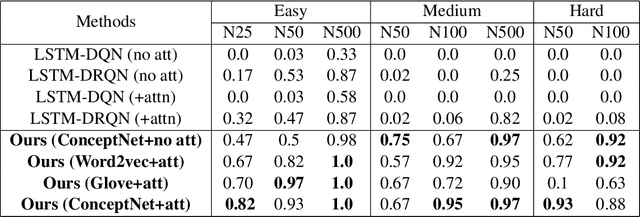
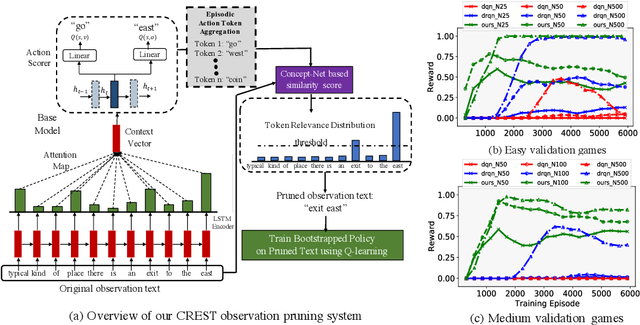
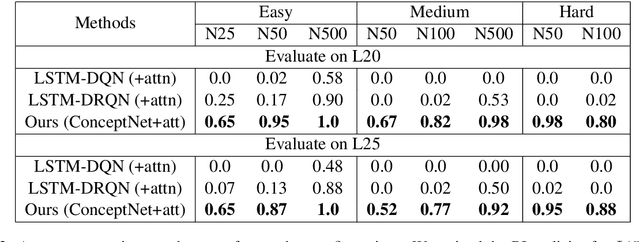
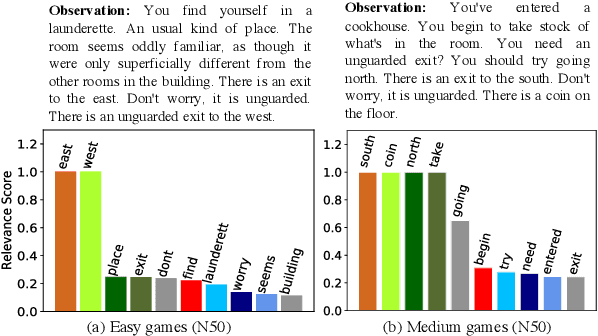
We show that Reinforcement Learning (RL) methods for solving Text-Based Games (TBGs) often fail to generalize on unseen games, especially in small data regimes. To address this issue, we propose Context Relevant Episodic State Truncation (CREST) for irrelevant token removal in observation text for improved generalization. Our method first trains a base model using Q-learning, which typically overfits the training games. The base model's action token distribution is used to perform observation pruning that removes irrelevant tokens. A second bootstrapped model is then retrained on the pruned observation text. Our bootstrapped agent shows improved generalization in solving unseen TextWorld games, using 10x-20x fewer training games compared to previous state-of-the-art methods despite requiring less number of training episodes.