 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Embeddings, Better Sequence Labelers?
Paper and Code
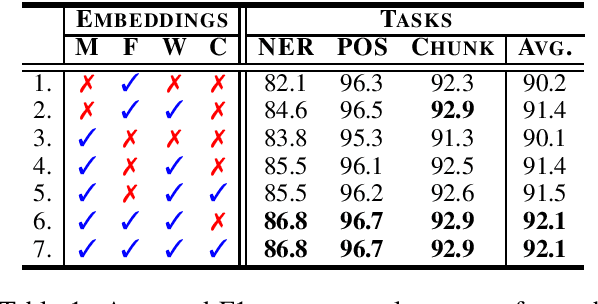
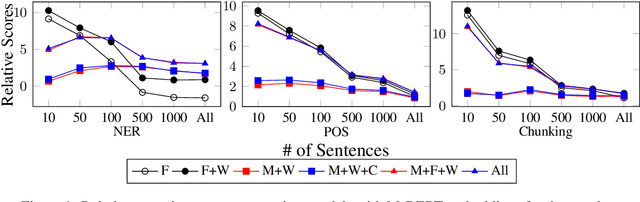

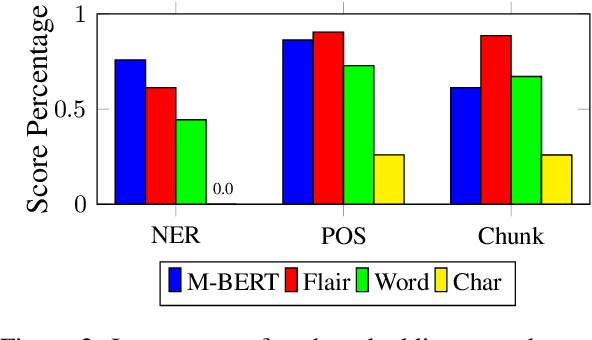
Recent work proposes a family of contextual embeddings that significantly improves the accuracy of sequence labelers over non-contextual embeddings. However, there is no definite conclusion on whether we can build better sequence labelers by combining different kinds of embeddings in various settings. In this paper, we conduct extensive experiments on 3 tasks over 18 datasets and 8 languages to study the accuracy of sequence labeling with various embedding concatenations and make three observations: (1) concatenating more embedding variants leads to better accuracy in rich-resource and cross-domain settings and some conditions of low-resource settings; (2) concatenating additional contextual sub-word embeddings with contextual character embeddings hurts the accuracy in extremely low-resource settings; (3) based on the conclusion of (1), concatenating additional similar contextual embeddings cannot lead to further improvements. We hope these conclusions can help people build stronger sequence labelers in various settings.