 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Semantic Fusion Network for Video Object Detection
Paper and Code
Sep 16, 2020
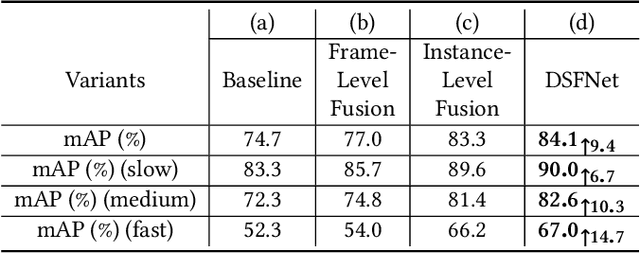
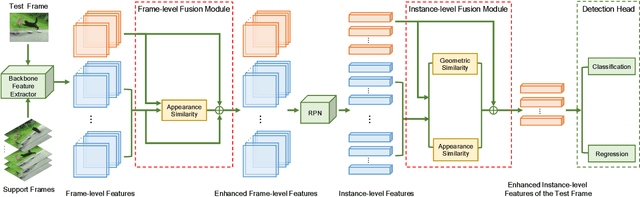
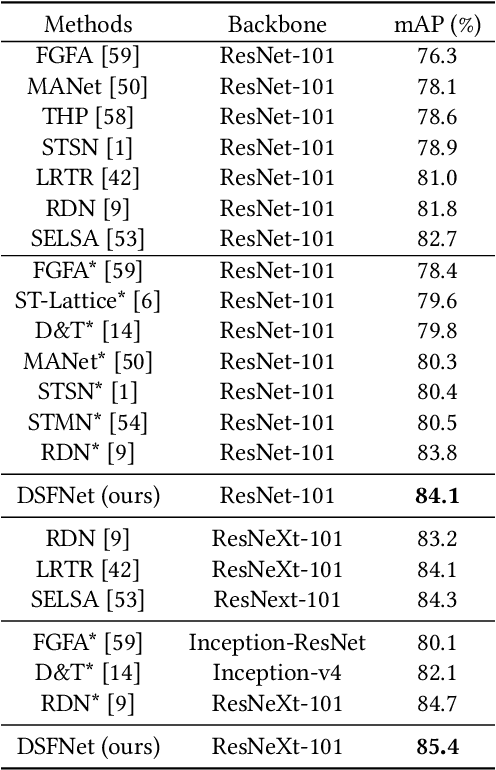
Video object detection is a tough task due to the deteriorated quality of video sequences captured under complex environments. Currently, this area is dominated by a series of feature enhancement based methods, which distill beneficial semantic information from multiple frames and generate enhanced features through fusing the distilled information. However, the distillation and fusion operations are usually performed at either frame level or instance level with external guidance using additional information, such as optical flow and feature memory. In this work, we propose a dual semantic fusion network (abbreviated as DSFNet) to fully exploit both frame-level and instance-level semantics in a unified fusion framework without external guidance. Moreover, we introduce a geometric similarity measure into the fusion process to alleviate the influence of information distortion caused by noise. As a result, the proposed DSFNet can generate more robust features through the multi-granularity fusion and avoid being affected by the instability of external guidance. To evaluate the proposed DSFNet, we conduct extensive experiments on the ImageNet VID dataset. Notably, the proposed dual semantic fusion network achieves, to the best of our knowledge, the best performance of 84.1\% mAP among the current state-of-the-art video object detectors with ResNet-101 and 85.4\% mAP with ResNeXt-101 without using any post-processing steps.