 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny-to-Many Voice Conversion with Location-Relative Sequence-to-Sequence Modeling
Paper and Code
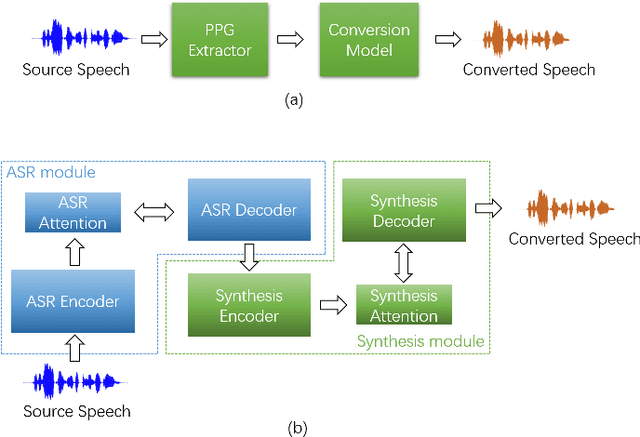
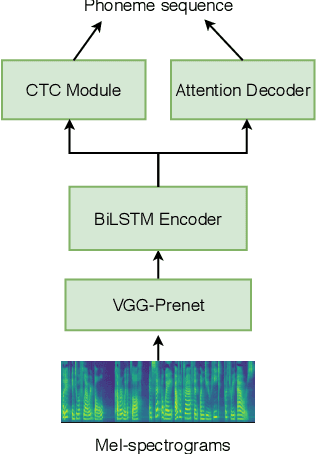
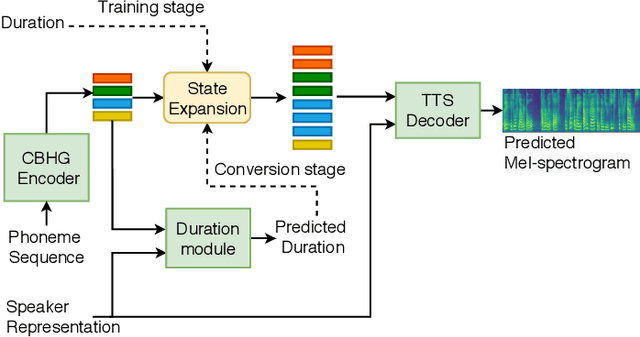
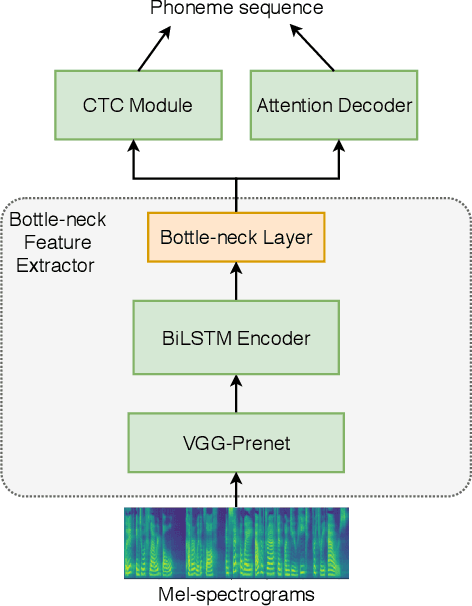
This paper proposes an any-to-many location-relative, sequence-to-sequence (seq2seq) based, non-parallel voice conversion approach. In this approach, we combine a bottle-neck feature extractor (BNE) with a seq2seq based synthesis module. During the training stage, an encoder-decoder based hybrid connectionist-temporal-classification-attention (CTC-attention) phoneme recognizer is trained, whose encoder has a bottle-neck layer. A BNE is obtained from the phoneme recognizer and is utilized to extract speaker-independent, dense and rich linguistic representations from spectral features. Then a multi-speaker location-relative attention based seq2seq synthesis model is trained to reconstruct spectral features from the bottle-neck features, conditioning on speaker representations for speaker identity control in the generated speech. To mitigate the difficulties of using seq2seq based models to align long sequences, we down-sample the input spectral feature along the temporal dimension and equip the synthesis model with a discretized mixture of logistic (MoL) attention mechanism. Since the phoneme recognizer is trained with large speech recognition data corpus, the proposed approach can conduct any-to-many voice conversion. Objective and subjective evaluations shows that the proposed any-to-many approach has superior voice conversion performance in terms of both naturalness and speaker similarity. Ablation studies are conducted to confirm the effectiveness of feature selection and model design strategies in the proposed approach. The proposed VC approach can readily be extended to support any-to-any VC (also known as one/few-shot VC), and achieve high performance according to objective and subjective evaluations.