 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptualized Representation Learning for Chinese Biomedical Text Mining
Paper and Code
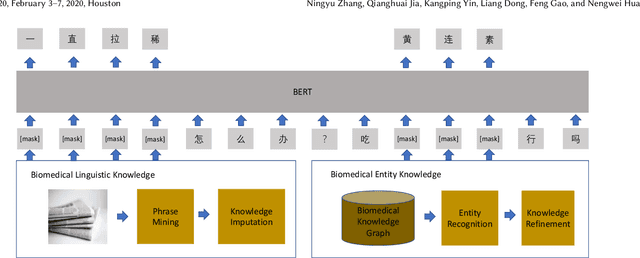

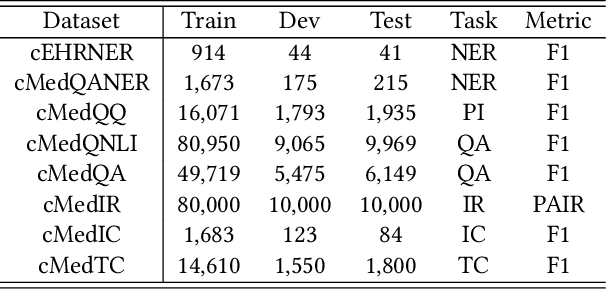
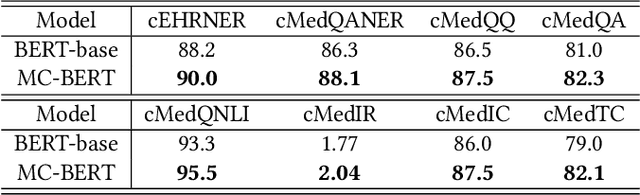
Biomedical text mining is becoming increasingly important as the number of biomedical documents and web data rapidly grows. Recently, word representation models such as BERT has gained popularity among researchers. However, it is difficult to estimate their performance on datasets containing biomedical texts as the word distributions of general and biomedical corpora are quite different. Moreover, the medical domain has long-tail concepts and terminologies that are difficult to be learned via language models. For the Chinese biomedical text, it is more difficult due to its complex structure and the variety of phrase combinations. In this paper, we investigate how the recently introduced pre-trained language model BERT can be adapted for Chinese biomedical corpora and propose a novel conceptualized representation learning approach. We also release a new Chinese Biomedical Language Understanding Evaluation benchmark (\textbf{ChineseBLUE}). We examine the effectiveness of Chinese pre-trained models: BERT, BERT-wwm, RoBERTa, and our approach. Experimental results on the benchmark show that our approach could bring significant gain. We release the pre-trained model on GitHub: https://github.com/alibaba-research/ChineseBLUE.