 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Entropy Coding for Efficient Video Compression
Paper and Code
Aug 20, 2020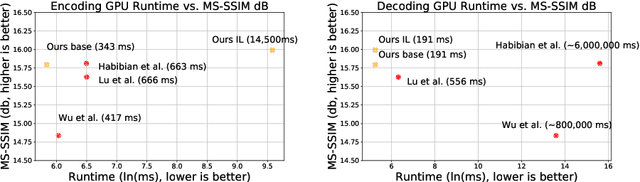
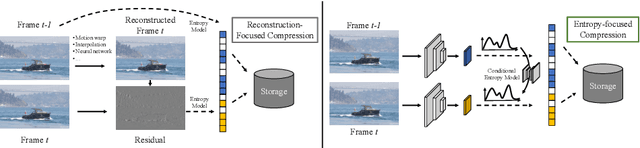
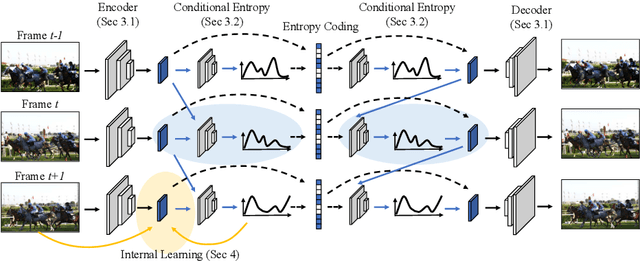
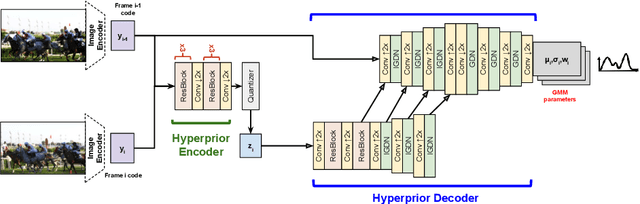
We propose a very simple and efficient video compression framework that only focuses on modeling the conditional entropy between frames. Unlike prior learning-based approaches, we reduce complexity by not performing any form of explicit transformations between frames and assume each frame is encoded with an independent state-of-the-art deep image compressor. We first show that a simple architecture modeling the entropy between the image latent codes is as competitive as other neural video compression works and video codecs while being much faster and easier to implement. We then propose a novel internal learning extension on top of this architecture that brings an additional 10% bitrate savings without trading off decoding speed. Importantly, we show that our approach outperforms H.265 and other deep learning baselines in MS-SSIM on higher bitrate UVG video, and against all video codecs on lower framerates, while being thousands of times faster in decoding than deep models utilizing an autoregressive entropy model.