 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Image-to-Image Translation via Mutual Information Estimation and Maximization
Paper and Code
Sep 06, 2020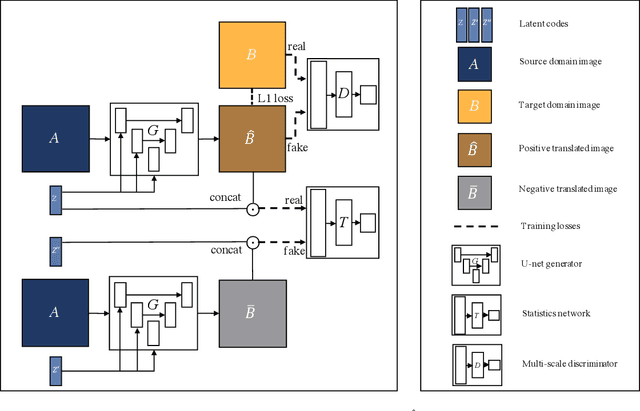
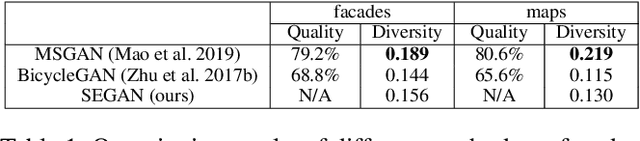

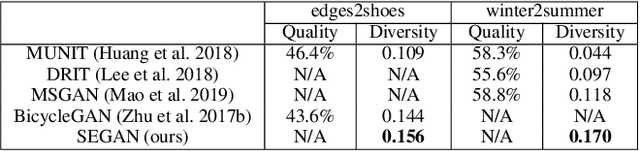
In this paper, we present a novel framework that can achieve multimodal image-to-image translation by simply encouraging the statistical dependence between the latent code and the output image in conditional generative adversarial networks. In addition, by incorporating a U-net generator into our framework, our method only needs to learn a one-sided translation model from the source image domain to the target image domain for both supervised and unsupervised multimodal image-to-image translation. Furthermore, our method also achieves disentanglement between the source domain content and the target domain style for free. We conduct experiments under supervised and unsupervised settings on various benchmark image-to-image translation datasets compared with the state-of-the-art methods, showing the effectiveness and simplicity of our method to achieve multimodal and high-quality results.