 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from a Complementary-label Source Domain: Theory and Algorithms
Paper and Code
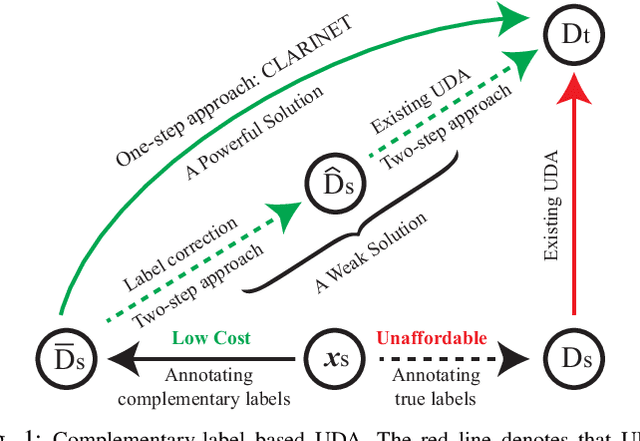

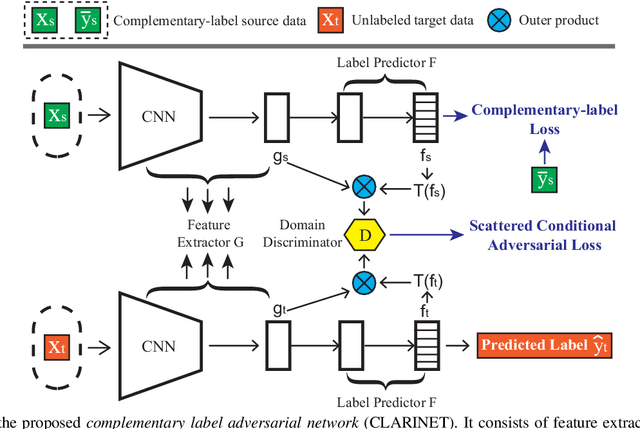
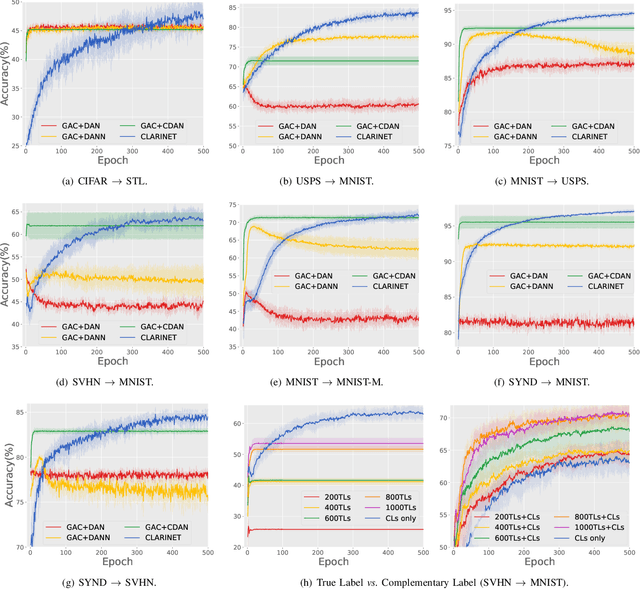
In unsupervised domain adaptation (UDA), a classifier for the target domain is trained with massive true-label data from the source domain and unlabeled data from the target domain. However, collecting fully-true-label data in the source domain is high-cost and sometimes impossible. Compared to the true labels, a complementary label specifies a class that a pattern does not belong to, hence collecting complementary labels would be less laborious than collecting true labels. Thus, in this paper, we propose a novel setting that the source domain is composed of complementary-label data, and a theoretical bound for it is first proved. We consider two cases of this setting, one is that the source domain only contains complementary-label data (completely complementary unsupervised domain adaptation, CC-UDA), and the other is that the source domain has plenty of complementary-label data and a small amount of true-label data (partly complementary unsupervised domain adaptation, PC-UDA). To this end, a complementary label adversarial network} (CLARINET) is proposed to solve CC-UDA and PC-UDA problems. CLARINET maintains two deep networks simultaneously, where one focuses on classifying complementary-label source data and the other takes care of source-to-target distributional adaptation. Experiments show that CLARINET significantly outperforms a series of competent baselines on handwritten-digits-recognition and objects-recognition tasks.