 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Overlook the Support Set: Towards Improving Generalization in Meta-learning
Paper and Code
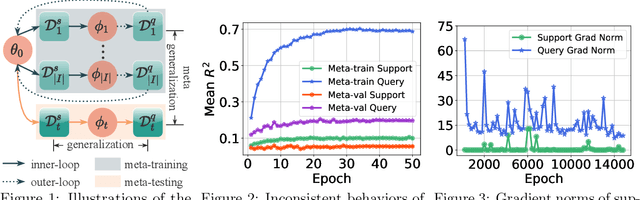
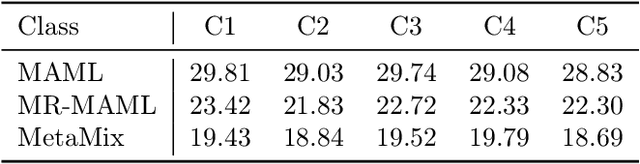
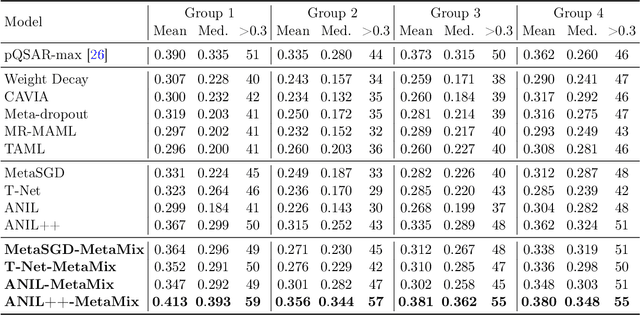
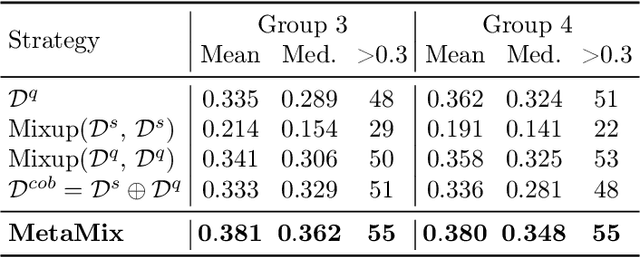
Meta-learning has proven to be a powerful paradigm for transferring the knowledge from previously tasks to facilitate the learning of a novel task. Current dominant algorithms train a well-generalized model initialization which is adapted to each task via the support set. The crux, obviously, lies in optimizing the generalization capability of the initialization, which is measured by the performance of the adapted model on the query set of each task. Unfortunately, this generalization measure, evidenced by empirical results, pushes the initialization to overfit the query but fail the support set, which significantly impairs the generalization and adaptation to novel tasks. To address this issue, we include the support set when evaluating the generalization to produce a new meta-training strategy, MetaMix, that linearly combines the input and hidden representations of samples from both the support and query sets. Theoretical studies on classification and regression tasks show how MetaMix can improve the generalization of meta-learning. More remarkably, MetaMix obtains state-of-the-art results by a large margin across many datasets and remains compatible with existing meta-learning algorithms.