Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Video Synthesis with Action Graphs
Paper and Code
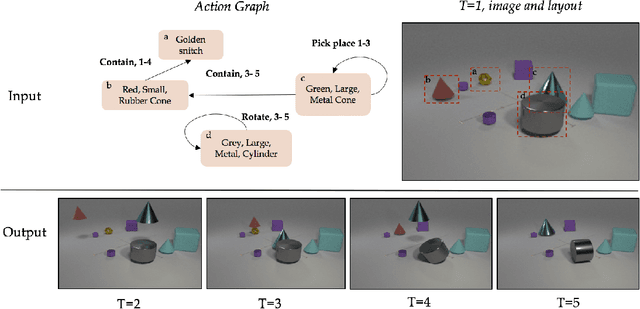
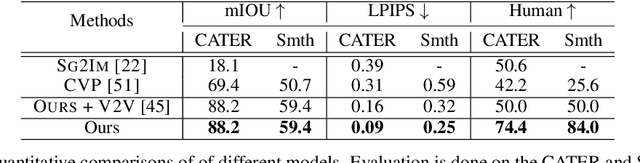
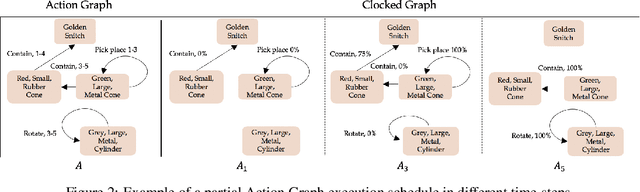
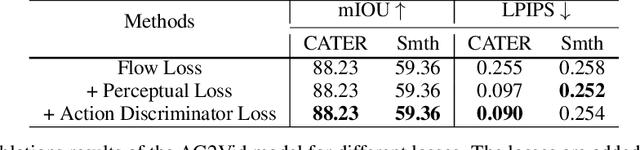
Videos of actions are complex spatio-temporal signals, containing rich compositional structures. Current generative models are limited in their ability to generate examples of object configurations outside the range they were trained on. Towards this end, we introduce a generative model (AG2Vid) based on Action Graphs, a natural and convenient structure that represents the dynamics of actions between objects over time. Our AG2Vid model disentangles appearance and position features, allowing for more accurate generation. AG2Vid is evaluated on the CATER and Something-Something datasets and outperforms other baselines. Finally, we show how Action Graphs can be used for generating novel compositions of unseen actions.
View paper on
 OpenReview
OpenReview