 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Expansive Reward Learning: Rethinking Human Input
Paper and Code
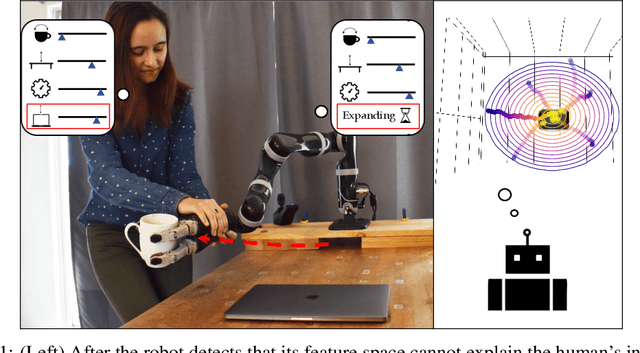

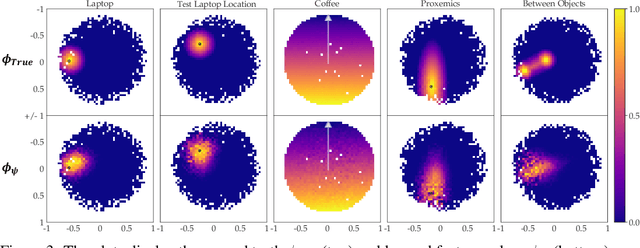
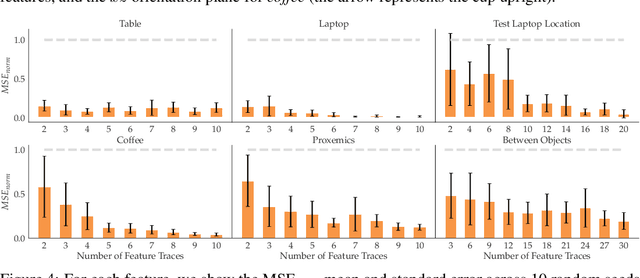
In collaborative human-robot scenarios, when a person is not satisfied with how a robot performs a task, they can intervene to correct it. Reward learning methods enable the robot to adapt its reward function online based on such human input. However, this online adaptation requires low sample complexity algorithms which rely on simple functions of handcrafted features. In practice, pre-specifying an exhaustive set of features the person might care about is impossible; what should the robot do when the human correction cannot be explained by the features it already has access to? Recent progress in deep Inverse Reinforcement Learning (IRL) suggests that the robot could fall back on demonstrations: ask the human for demonstrations of the task, and recover a reward defined over not just the known features, but also the raw state space. Our insight is that rather than implicitly learning about the missing feature(s) from task demonstrations, the robot should instead ask for data that explicitly teaches it about what it is missing. We introduce a new type of human input, in which the person guides the robot from areas of the state space where the feature she is teaching is highly expressed to states where it is not. We propose an algorithm for learning the feature from the raw state space and integrating it into the reward function. By focusing the human input on the missing feature, our method decreases sample complexity and improves generalization of the learned reward over the above deep IRL baseline. We show this in experiments with a 7DOF robot manipulator. Finally, we discuss our method's potential implications for deep reward learning more broadly: taking a divide-and-conquer approach that focuses on important features separately before learning from demonstrations can improve generalization in tasks where such features are easy for the human to teach.