 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Convergence Rate of One-Point Zeroth-Order Optimization using Residual Feedback
Paper and Code
Jun 18, 2020
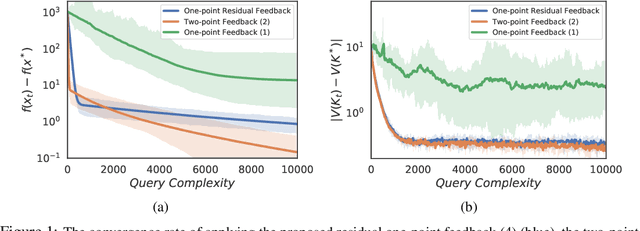
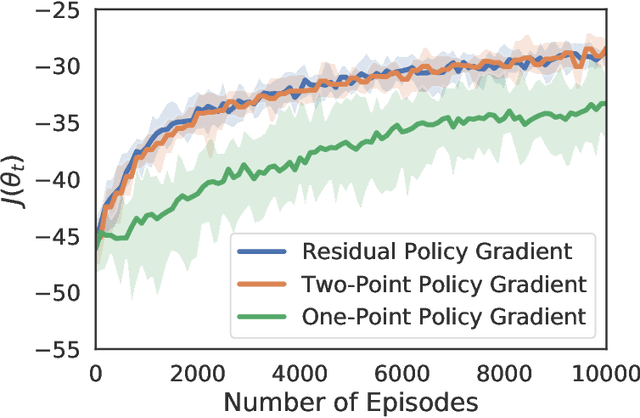
Many existing zeroth-order optimization (ZO) algorithms adopt two-point feedback schemes due to their fast convergence rate compared to one-point feedback schemes. However, two-point schemes require two evaluations of the objective function at each iteration, which can be impractical in applications where the data are not all available a priori, e.g., in online optimization. In this paper, we propose a novel one-point feedback scheme that queries the function value only once at each iteration and estimates the gradient using the residual between two consecutive feedback points. When optimizing a deterministic Lipschitz function, we show that the query complexity of ZO with the proposed one-point residual feedback matches that of ZO with the existing two-point feedback schemes. Moreover, the query complexity of the proposed algorithm can be improved when the objective function has Lipschitz gradient. Then, for stochastic bandit optimization problems, we show that ZO with one-point residual feedback achieves the same convergence rate as that of ZO with two-point feedback with uncontrollable data samples. We demonstrate the effectiveness of the proposed one-point residual feedback via extensive numerical experiments.