 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGive Me Something to Eat: Referring Expression Comprehension with Commonsense Knowledge
Paper and Code

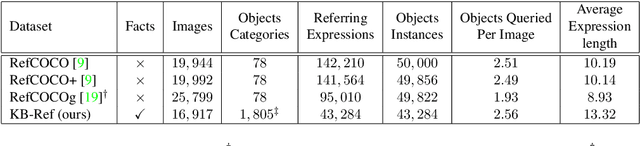
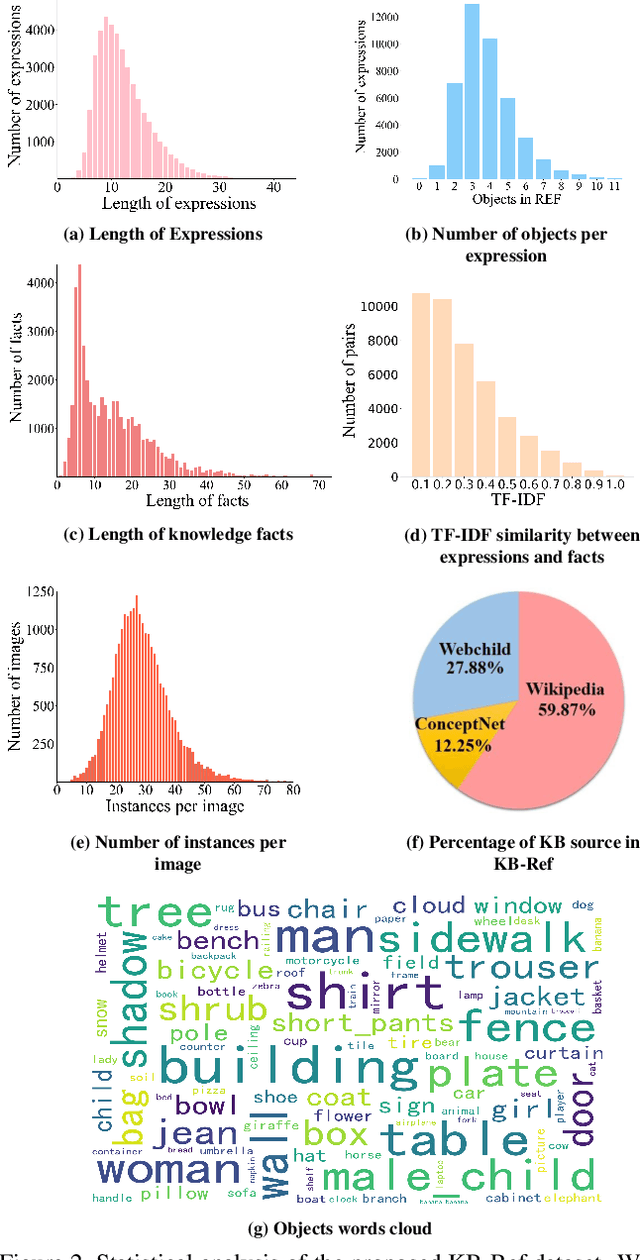
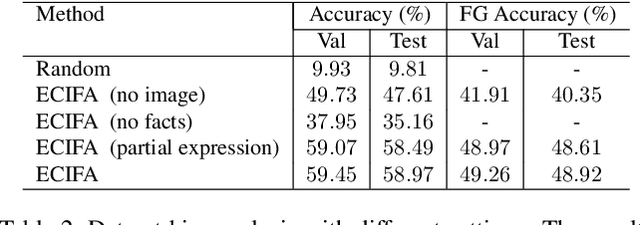
Conventional referring expression comprehension (REF) assumes people to query something from an image by describing its visual appearance and spatial location, but in practice, we often ask for an object by describing its affordance or other non-visual attributes, especially when we do not have a precise target. For example, sometimes we say 'Give me something to eat'. In this case, we need to use commonsense knowledge to identify the objects in the image. Unfortunately, these is no existing referring expression dataset reflecting this requirement, not to mention a model to tackle this challenge. In this paper, we collect a new referring expression dataset, called KB-Ref, containing 43k expressions on 16k images. In KB-Ref, to answer each expression (detect the target object referred by the expression), at least one piece of commonsense knowledge must be required. We then test state-of-the-art (SoTA) REF models on KB-Ref, finding that all of them present a large drop compared to their outstanding performance on general REF datasets. We also present an expression conditioned image and fact attention (ECIFA) network that extract information from correlated image regions and commonsense knowledge facts. Our method leads to a significant improvement over SoTA REF models, although there is still a gap between this strong baseline and human performance. The dataset and baseline models will be released.