 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Distributed Deep Learning: Survey, Evaluation, and Challenges
Paper and Code
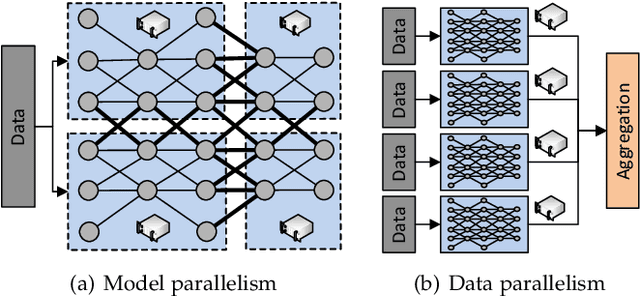
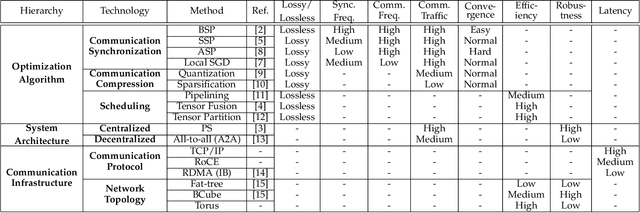
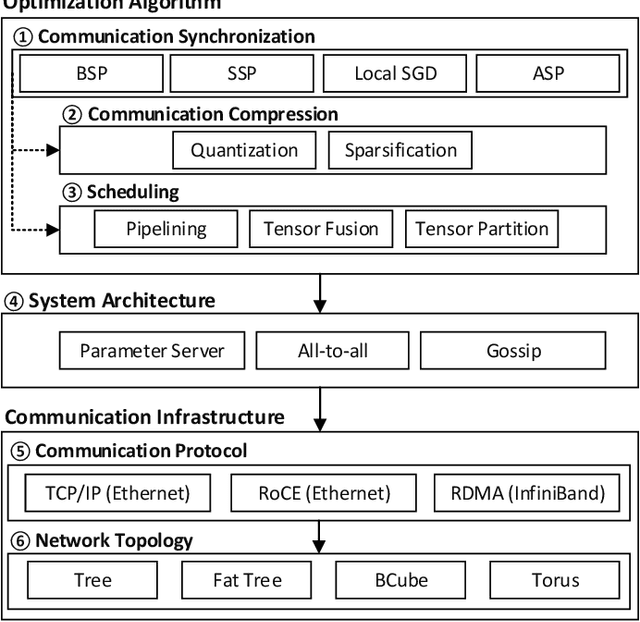

In recent years, distributed deep learning techniques are widely deployed to accelerate the training of deep learning models by exploiting multiple computing nodes. However, the extensive communications among workers dramatically limit the system scalability. In this article, we provide a systematic survey of communication-efficient distributed deep learning. Specifically, we first identify the communication challenges in distributed deep learning. Then we summarize the state-of-the-art techniques in this direction, and provide a taxonomy with three levels: optimization algorithm, system architecture, and communication infrastructure. Afterwards, we present a comparative study on seven different distributed deep learning techniques on a 32-GPU cluster with both 10Gbps Ethernet and 100Gbps InfiniBand. We finally discuss some challenges and open issues for possible future investigations.