 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASAPP-ASR: Multistream CNN and Self-Attentive SRU for SOTA Speech Recognition
Paper and Code
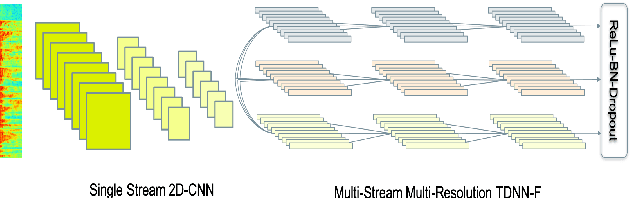
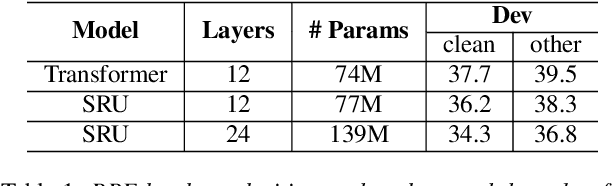
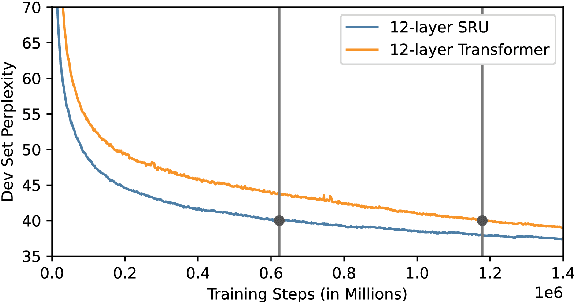
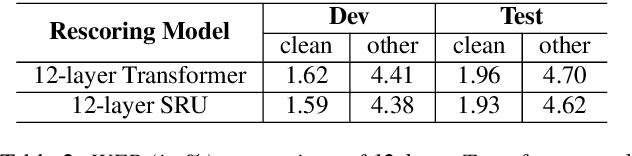
In this paper we present state-of-the-art (SOTA) performance on the LibriSpeech corpus with two novel neural network architectures, a multistream CNN for acoustic modeling and a self-attentive simple recurrent unit (SRU) for language modeling. In the hybrid ASR framework, the multistream CNN acoustic model processes an input of speech frames in multiple parallel pipelines where each stream has a unique dilation rate for diversity. Trained with the SpecAugment data augmentation method, it achieves relative word error rate (WER) improvements of 4% on test-clean and 14% on test-other. We further improve the performance via N-best rescoring using a 24-layer self-attentive SRU language model, achieving WERs of 1.75% on test-clean and 4.46% on test-other.