 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter Matters: Video Story Understanding with Character-Aware Relations
Paper and Code
May 09, 2020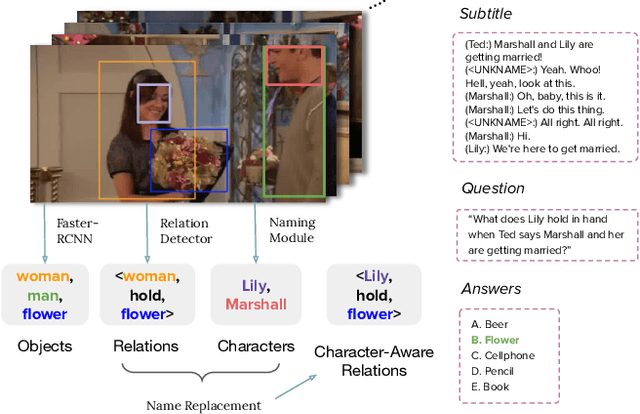
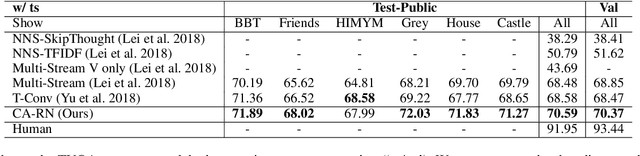
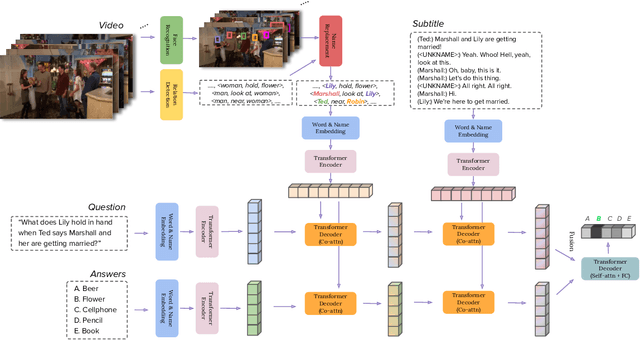
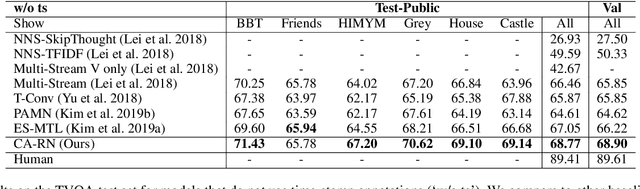
Different from short videos and GIFs, video stories contain clear plots and lists of principal characters. Without identifying the connection between appearing people and character names, a model is not able to obtain a genuine understanding of the plots. Video Story Question Answering (VSQA) offers an effective way to benchmark higher-level comprehension abilities of a model. However, current VSQA methods merely extract generic visual features from a scene. With such an approach, they remain prone to learning just superficial correlations. In order to attain a genuine understanding of who did what to whom, we propose a novel model that continuously refines character-aware relations. This model specifically considers the characters in a video story, as well as the relations connecting different characters and objects. Based on these signals, our framework enables weakly-supervised face naming through multi-instance co-occurrence matching and supports high-level reasoning utilizing Transformer structures. We train and test our model on the six diverse TV shows in the TVQA dataset, which is by far the largest and only publicly available dataset for VSQA. We validate our proposed approach over TVQA dataset through extensive ablation study.