 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Wise Cross-View Decoding for Sequence-to-Sequence Learning
Paper and Code
Jun 03, 2020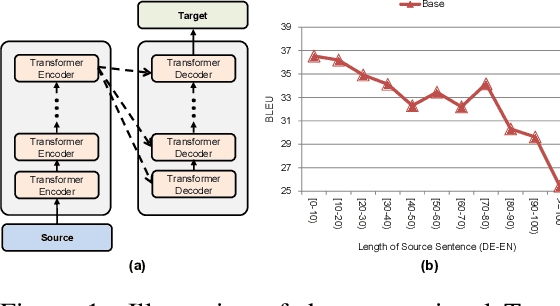
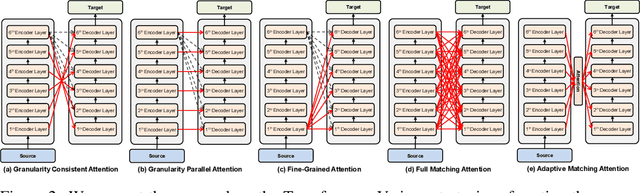
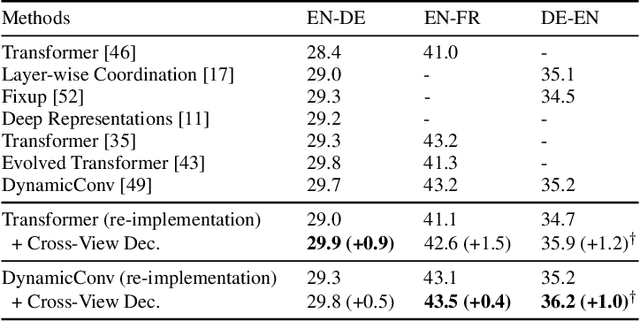
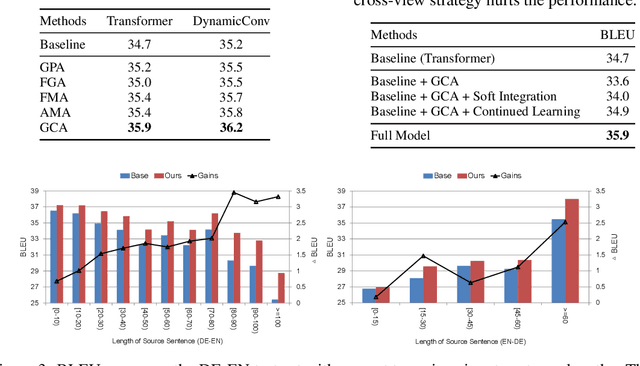
In sequence-to-sequence learning, the attention mechanism has been a great success in bridging the information between the encoder and the decoder. However, it is often overlooked that the decoder obtains only a single view of the source sequences, i.e., the representations generated by the last encoder layer. Although those representations are supposed to be a comprehensive, global view of source sequences, such practice keeps the decoders from concrete, fine-grained source information generated by other encoder layers. In this work, we propose to encourage the decoder to take the full advantage of the multi-level source representations for layer-wise cross-view decoding. Concretely, different views of the source sequences are presented to different decoder layers and multiple strategies are explored to route the source representations. In particular, the granularity consistent attention (GCA) strategy proves the most efficient and effective in the experiments on the neural machine translation task, surpassing the previous state-of-the-art architecture on three benchmark datasets.