 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversifying Dialogue Generation with Non-Conversational Text
Paper and Code
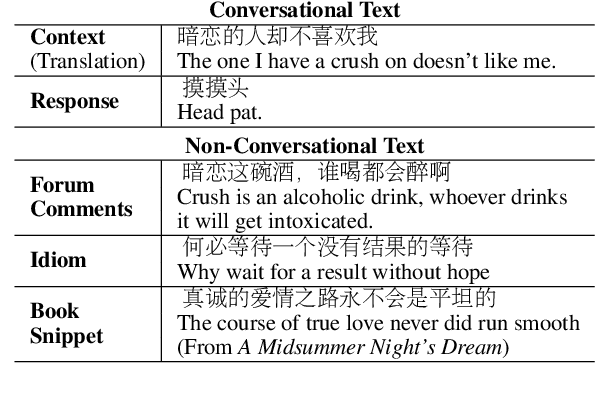
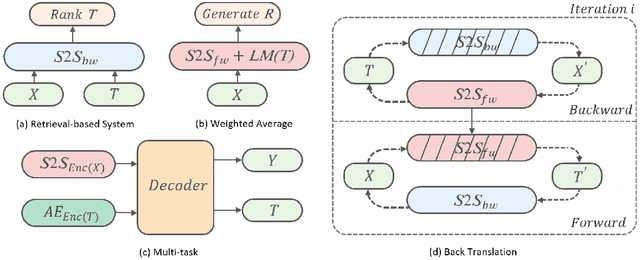
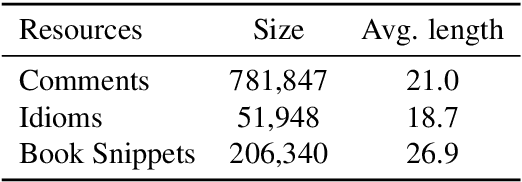
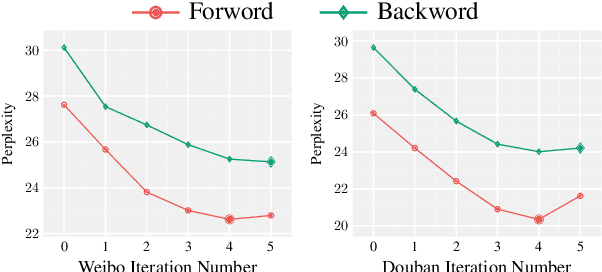
Neural network-based sequence-to-sequence (seq2seq) models strongly suffer from the low-diversity problem when it comes to open-domain dialogue generation. As bland and generic utterances usually dominate the frequency distribution in our daily chitchat, avoiding them to generate more interesting responses requires complex data filtering, sampling techniques or modifying the training objective. In this paper, we propose a new perspective to diversify dialogue generation by leveraging non-conversational text. Compared with bilateral conversations, non-conversational text are easier to obtain, more diverse and cover a much broader range of topics. We collect a large-scale non-conversational corpus from multi sources including forum comments, idioms and book snippets. We further present a training paradigm to effectively incorporate these text via iterative back translation. The resulting model is tested on two conversational datasets and is shown to produce significantly more diverse responses without sacrificing the relevance with context.