 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquilibrium Propagation with Continual Weight Updates
Paper and Code
Apr 29, 2020
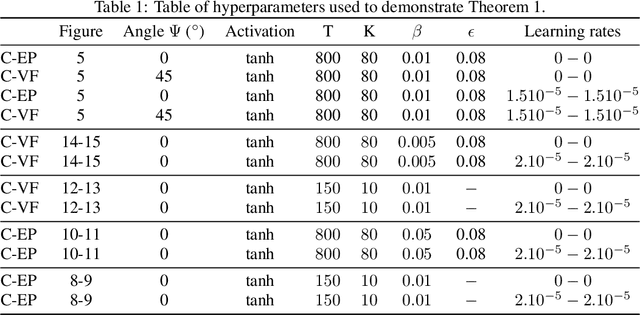
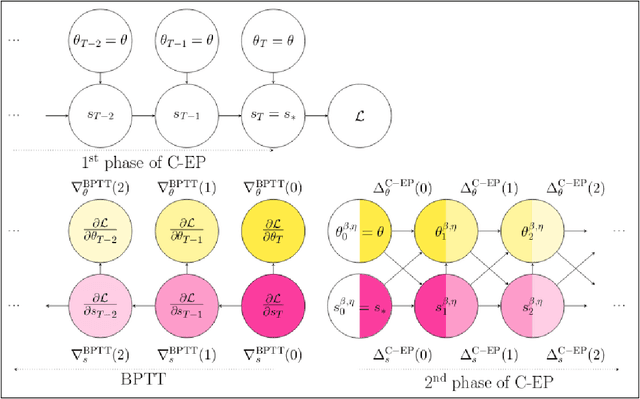
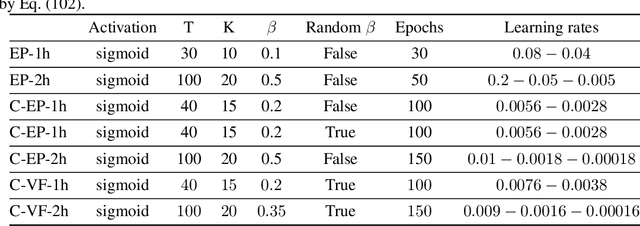
Equilibrium Propagation (EP) is a learning algorithm that bridges Machine Learning and Neuroscience, by computing gradients closely matching those of Backpropagation Through Time (BPTT), but with a learning rule local in space. Given an input $x$ and associated target $y$, EP proceeds in two phases: in the first phase neurons evolve freely towards a first steady state; in the second phase output neurons are nudged towards $y$ until they reach a second steady state. However, in existing implementations of EP, the learning rule is not local in time: the weight update is performed after the dynamics of the second phase have converged and requires information of the first phase that is no longer available physically. In this work, we propose a version of EP named Continual Equilibrium Propagation (C-EP) where neuron and synapse dynamics occur simultaneously throughout the second phase, so that the weight update becomes local in time. Such a learning rule local both in space and time opens the possibility of an extremely energy efficient hardware implementation of EP. We prove theoretically that, provided the learning rates are sufficiently small, at each time step of the second phase the dynamics of neurons and synapses follow the gradients of the loss given by BPTT (Theorem 1). We demonstrate training with C-EP on MNIST and generalize C-EP to neural networks where neurons are connected by asymmetric connections. We show through experiments that the more the network updates follows the gradients of BPTT, the best it performs in terms of training. These results bring EP a step closer to biology by better complying with hardware constraints while maintaining its intimate link with backpropagation.