 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Natural Language Instructions to Mobile UI Action Sequences
Paper and Code
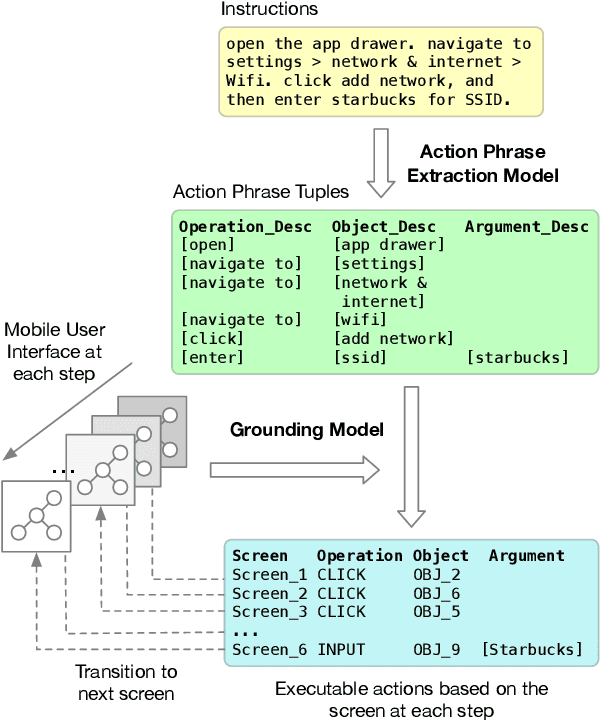
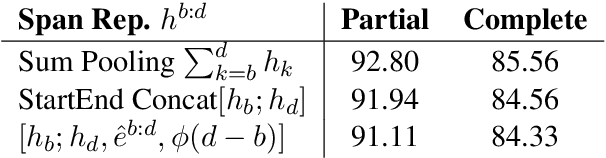
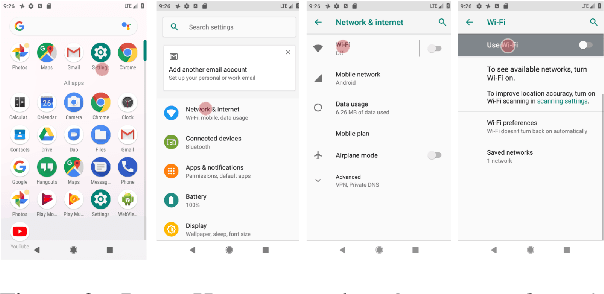
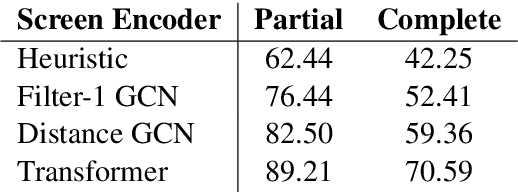
We present a new problem: grounding natural language instructions to mobile user interface actions, and create three new datasets for it. For full task evaluation, we create PIXELHELP, a corpus that pairs English instructions with actions performed by people on a mobile UI emulator. To scale training, we decouple the language and action data by (a) annotating action phrase spans in HowTo instructions and (b) synthesizing grounded descriptions of actions for mobile user interfaces. We use a Transformer to extract action phrase tuples from long-range natural language instructions. A grounding Transformer then contextually represents UI objects using both their content and screen position and connects them to object descriptions. Given a starting screen and instruction, our model achieves 70.59% accuracy on predicting complete ground-truth action sequences in PIXELHELP.