 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIMELY: Pushing Data Movements and Interfaces in PIM Accelerators Towards Local and in Time Domain
Paper and Code
May 03, 2020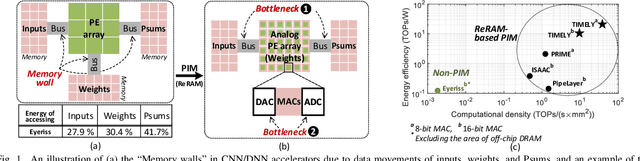
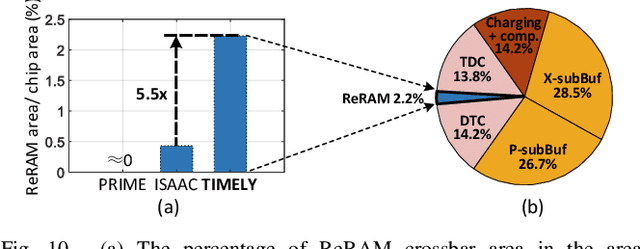
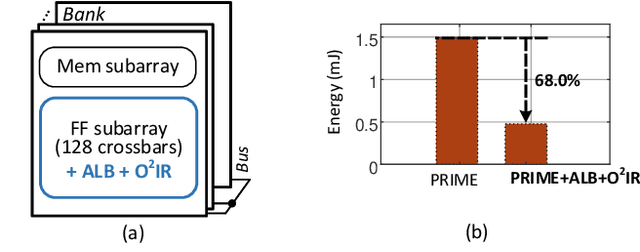
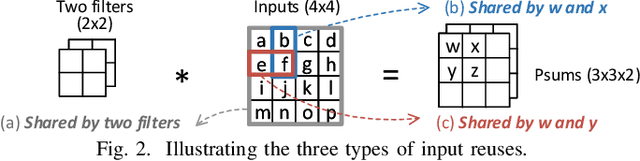
Resistive-random-access-memory (ReRAM) based processing-in-memory (R$^2$PIM) accelerators show promise in bridging the gap between Internet of Thing devices' constrained resources and Convolutional/Deep Neural Networks' (CNNs/DNNs') prohibitive energy cost. Specifically, R$^2$PIM accelerators enhance energy efficiency by eliminating the cost of weight movements and improving the computational density through ReRAM's high density. However, the energy efficiency is still limited by the dominant energy cost of input and partial sum (Psum) movements and the cost of digital-to-analog (D/A) and analog-to-digital (A/D) interfaces. In this work, we identify three energy-saving opportunities in R$^2$PIM accelerators: analog data locality, time-domain interfacing, and input access reduction, and propose an innovative R$^2$PIM accelerator called TIMELY, with three key contributions: (1) TIMELY adopts analog local buffers (ALBs) within ReRAM crossbars to greatly enhance the data locality, minimizing the energy overheads of both input and Psum movements; (2) TIMELY largely reduces the energy of each single D/A (and A/D) conversion and the total number of conversions by using time-domain interfaces (TDIs) and the employed ALBs, respectively; (3) we develop an only-once input read (O$^2$IR) mapping method to further decrease the energy of input accesses and the number of D/A conversions. The evaluation with more than 10 CNN/DNN models and various chip configurations shows that, TIMELY outperforms the baseline R$^2$PIM accelerator, PRIME, by one order of magnitude in energy efficiency while maintaining better computational density (up to 31.2$\times$) and throughput (up to 736.6$\times$). Furthermore, comprehensive studies are performed to evaluate the effectiveness of the proposed ALB, TDI, and O$^2$IR innovations in terms of energy savings and area reduction.