 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMM: A Recursive Mental Model for Dialog Navigation
Paper and Code
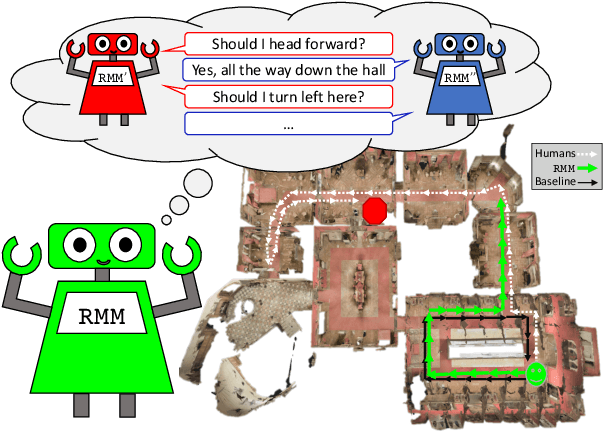
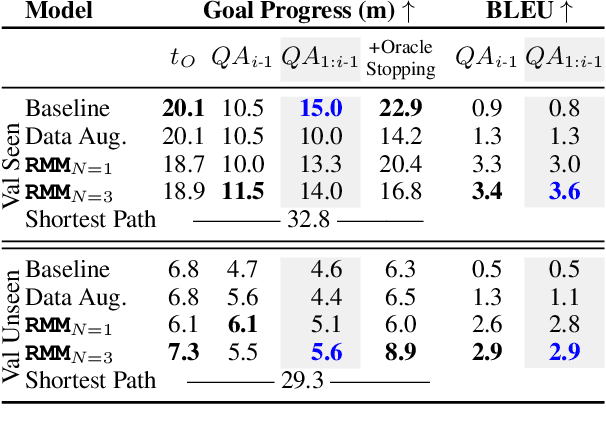
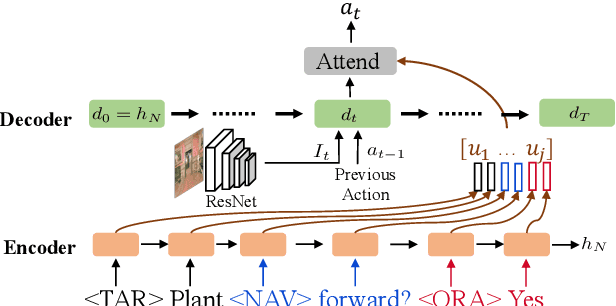

Fluent communication requires understanding your audience. In the new collaborative task of Vision-and-Dialog Navigation, one agent must ask questions and follow instructive answers, while the other must provide those answers. We introduce the first true dialog navigation agents in the literature which generate full conversations, and introduce the Recursive Mental Model (RMM) to conduct these dialogs. RMM dramatically improves generated language questions and answers by recursively propagating reward signals to find the question expected to elicit the best answer, and the answer expected to elicit the best navigation. Additionally, we provide baselines for future work to build on when investigating the unique challenges of embodied visual agents that not only interpret instructions but also ask questions in natural language.