 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Characterizing Adversarial Defects of Deep Learning Software from the Lens of Uncertainty
Paper and Code
Apr 24, 2020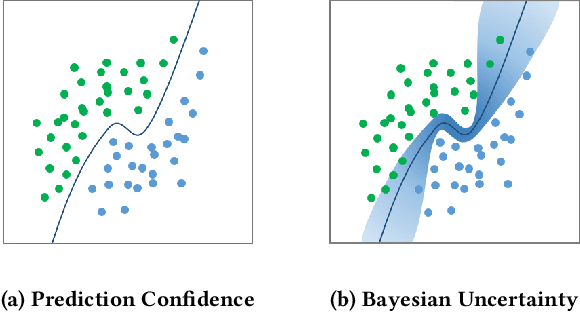
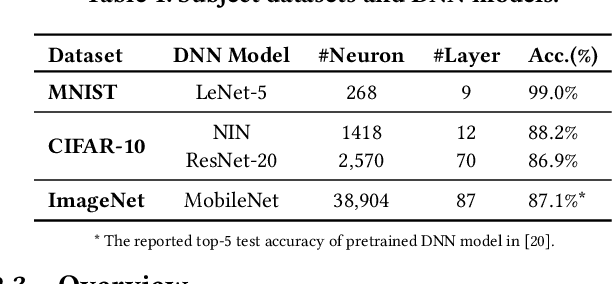
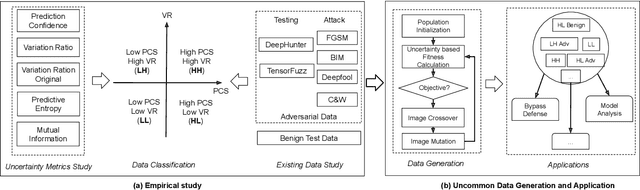
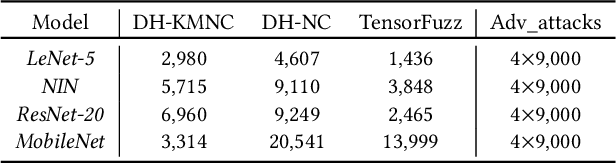
Over the past decade, deep learning (DL) has been successfully applied to many industrial domain-specific tasks. However, the current state-of-the-art DL software still suffers from quality issues, which raises great concern especially in the context of safety- and security-critical scenarios. Adversarial examples (AEs) represent a typical and important type of defects needed to be urgently addressed, on which a DL software makes incorrect decisions. Such defects occur through either intentional attack or physical-world noise perceived by input sensors, potentially hindering further industry deployment. The intrinsic uncertainty nature of deep learning decisions can be a fundamental reason for its incorrect behavior. Although some testing, adversarial attack and defense techniques have been recently proposed, it still lacks a systematic study to uncover the relationship between AEs and DL uncertainty. In this paper, we conduct a large-scale study towards bridging this gap. We first investigate the capability of multiple uncertainty metrics in differentiating benign examples (BEs) and AEs, which enables to characterize the uncertainty patterns of input data. Then, we identify and categorize the uncertainty patterns of BEs and AEs, and find that while BEs and AEs generated by existing methods do follow common uncertainty patterns, some other uncertainty patterns are largely missed. Based on this, we propose an automated testing technique to generate multiple types of uncommon AEs and BEs that are largely missed by existing techniques. Our further evaluation reveals that the uncommon data generated by our method is hard to be defended by the existing defense techniques with the average defense success rate reduced by 35\%. Our results call for attention and necessity to generate more diverse data for evaluating quality assurance solutions of DL software.